A digital marketing agency’s pitch deck has carried the same proof points for a decade: rankings, traffic, conversions. Then a client opens ChatGPT, asks for the best vendor in their category, and watches three competitors get recommended while their own brand never appears.
None of the numbers in the deck explain why.
I work on this problem daily at Wellows. In Q1 2026 we tracked 471,698 prompts across ChatGPT, Google AI Overviews, Google AI Mode, Perplexity, and Gemini, which produced roughly 1.92 million AI responses and about 9.25 million citations.
The pattern that matters most for agencies isn’t dramatic. It’s structural. AI engines assemble answers from a small set of cited sources, and those sources are the only layer of the system an agency can directly influence.
This guide treats AI visibility for digital marketing agencies as an operating problem, not a trend piece: what to measure, why mention counts collapse under client scrutiny, the citation-first workflow we run inside Wellows, and the deliverables that keep a retainer defensible when a client asks what they’re paying for.
- Score citations, not mentions. Citations are the URLs an engine actually pulled to build its answer. They’re the leading indicator an agency can act on; mentions are a lagging outcome.
- Split explicit from implicit. Explicit citations (the client’s own domain) route to content work. Implicit citations (third-party pages) route to outreach. One metric, two workflows.
- Track all five engines. The engines disagree on sources more than they agree, so a single-engine read misleads.
- Baseline before you touch anything. Without a day-zero Citation Score and competitor benchmark, no later report is believable.
- Report rates over time, never screenshots. AI answers vary between runs; only aggregated movement holds up.
What Does AI Visibility Mean for a Digital Marketing Agency?
AI visibility
AI visibility is how often, and how reliably, a brand appears inside AI-generated answers when buyers ask category questions. For an agency, the measurable unit is the citation: the source URL an AI engine pulled to construct its response. Rankings still feed the system, but the scoreboard has moved from position on a results page to inclusion in the answer itself.
The shift matters to digital marketing agencies more than to most businesses, because agencies sell measurement. A Pew Research Center study covered by Search Engine Land found that when an AI Overview appears, users click a traditional result about 8% of the time, against 15% when no summary is shown.
The demand didn’t disappear. It moved inside the answer, where your client either gets cited or gets skipped.
The discipline sits at the intersection of answer engine optimization and generative engine optimization. The two terms get used interchangeably, and they shouldn’t be; the AEO vs GEO breakdown separates what each one optimizes for.
For agency purposes, the practical version is this: AI engines read brands as entities, not pages. Before a model cites anyone, it resolves who solves the problem, who it’s for, and whether the source can be trusted. Agencies that treat this as keyword SEO with new vocabulary usually stall.
Why Mention Counts Fail as an Agency Metric
Most AI visibility reporting in circulation right now scores mention share: how often an LLM names the client’s brand, divided by total category mentions. It produces a tidy number.
It also collapses the first time a client asks the obvious follow-up: “so what do we do about it?”
The problem is what a mention actually is. When a model names a brand without citing a source, that mention often reflects training data. It varies between runs of the same prompt, it isn’t attached to any URL, and nobody on the team can be assigned to improve it.
Mentions are worth tracking for sentiment and share-of-voice context. They are a lagging outcome, not a lever.
Citations behave differently. A citation is the specific URL an engine retrieved to build its answer, which means every citation gap maps to a page someone can update or a publisher someone can pitch. That’s the entire argument for citation-level tracking: it’s the layer where measurement connects to work.

Mention vs Citations
Wellows separates citations into two types, because each one points to a different agency workflow:
- Explicit citations come from the client’s own domain. The engine cited their page directly. These belong to the content team: strengthen, restructure, and protect the page that’s already winning.
- Implicit citations come from third-party pages: a review site, a comparison listicle, a community thread. These belong to the outreach team: the engine trusts that source, so earning inclusion there converts into a citation.
In one Wellows project, tracked prompts produced 847 explicit citations (78.64%) and 230 implicit citations (21.36%).
That split isn’t trivia. It’s a resourcing decision: roughly four-fifths of that client’s citation footprint was ownable by the content team, and the remaining fifth was an outreach pipeline with named targets.

Explicit vs Implicit
✕ The mention-share report
“Your brand was mentioned 14 times across AI platforms this month.” No baseline, no competitor benchmark, no URLs, no next step. The client can’t tell whether 14 is progress, noise, or decline, and neither can the agency.
✓ The citation-share report
“Citation share on your 60 tracked commercial prompts moved from 11% to 17% since the March baseline. Here are the 9 new explicit citations with URLs, the 4 implicit citations we converted through outreach, and the 12 prompts where you’re still not mentioned, ranked by intent.” Every line is verifiable, and every gap has an owner.
One more measurement rule, and it’s non-negotiable. AI answers wobble between runs, so a single screenshot proves nothing in either direction. Rand Fishkin’s testing makes the same point: individual responses are inconsistent, but aggregate brand presence is measurable statistically across a large enough sample.
Track each prompt repeatedly across engines and report the rate. Anyone reporting from screenshots is reporting luck.
What 9.25 Million Citations Say About the Agency Job
Our Q1 2026 dataset covers 471,698 tracked prompts across five engines. Four findings reshape how a digital marketing agency should scope this work.
Share of citations in AI marketing answers that mention the brand itself
About 97% of what AI cites is third-party content: review sites, comparison listicles, communities, directories. Owned content alone cannot carry a client into AI answers, which makes earned placement and outreach core deliverables rather than add-ons.
Source: Wellows citation dataset, Q1 2026Citation slots in a typical AI answer
Google AI Overviews and AI Mode held steady at roughly 5.0 citations per answer through the quarter, and ChatGPT climbed from 3.6 to 5.0. Five slots per answer is the new page one. The job is winning one of those slots on a defined set of buyer prompts, not “ranking” everywhere.
Source: Wellows citation dataset, Q1 2026Share of tracked marketing prompts carrying commercial intent
More than a third of marketing-related AI conversations are best X and head-to-head comparison questions, which is where recommendations actually get decided. A client’s tracked prompt set should be weighted toward this slice.
Source: Wellows citation dataset, Q1 2026The fourth finding is the most encouraging one for agencies with mid-market clients. On marketing and SEO prompts, the engines cited 40,447 unique domains, and the top 10 domains captured only 15.5% of citations.
Roughly 72% of the citation volume sits in the long tail. There is no position-one monopoly in AI answers the way there is on a Google results page, which means a client without heavyweight domain authority can still earn citations on the prompts that matter to their revenue.
The Foundations That Make AI Visibility Trackable
Before any optimization, the brand has to be measurable and legible. Five foundations do most of that work, and they’re sequenced deliberately: the later ones are wasted effort without the earlier ones.
- Fix entity clarity first. Engines cite brands they can confidently identify. “We unlock growth for ambitious brands” gives a model nothing to attach to a query; “a paid-media analytics tool for DTC ecommerce brands” does. For most clients this is a one-day positioning fix that outperforms a month of new content.
- Structure pages so the answer can be lifted. Question-format headings, a direct 40-to-60-word answer at the top of the section, and FAQ schema make a page easy to quote. A buried answer hands the citation slot to whoever got to the point first.
- Harmonize the entity across channels. Organization schema with sameAs links, consistent naming and descriptions on the site, LinkedIn, and directory profiles. Inconsistent brand data makes the model guess, and it tends to guess in a competitor’s favor.
- Build third-party presence where engines already look. With ~97% of citations coming from external sources, a few placements in credible industry roundups and comparison reviews beat a pile of weak guest posts.
- Set the baseline before touching anything. Capture citation share, competitor citations, and the “brand not mentioned” prompt list at day zero. Every later claim of progress is measured against this snapshot.
How the Citation-First Workflow Runs Inside Wellows
Tactics without a system don’t survive a client roster. Inside Wellows, every client lives in its own project, with its own domain, competitor set, countries, engines, topics, and tracked prompts, so client twelve onboards the same way client one did.
The workflow runs in five stages, and the platform powers each one. It’s a loop, not a line: the report from one cycle sets the baseline for the next.
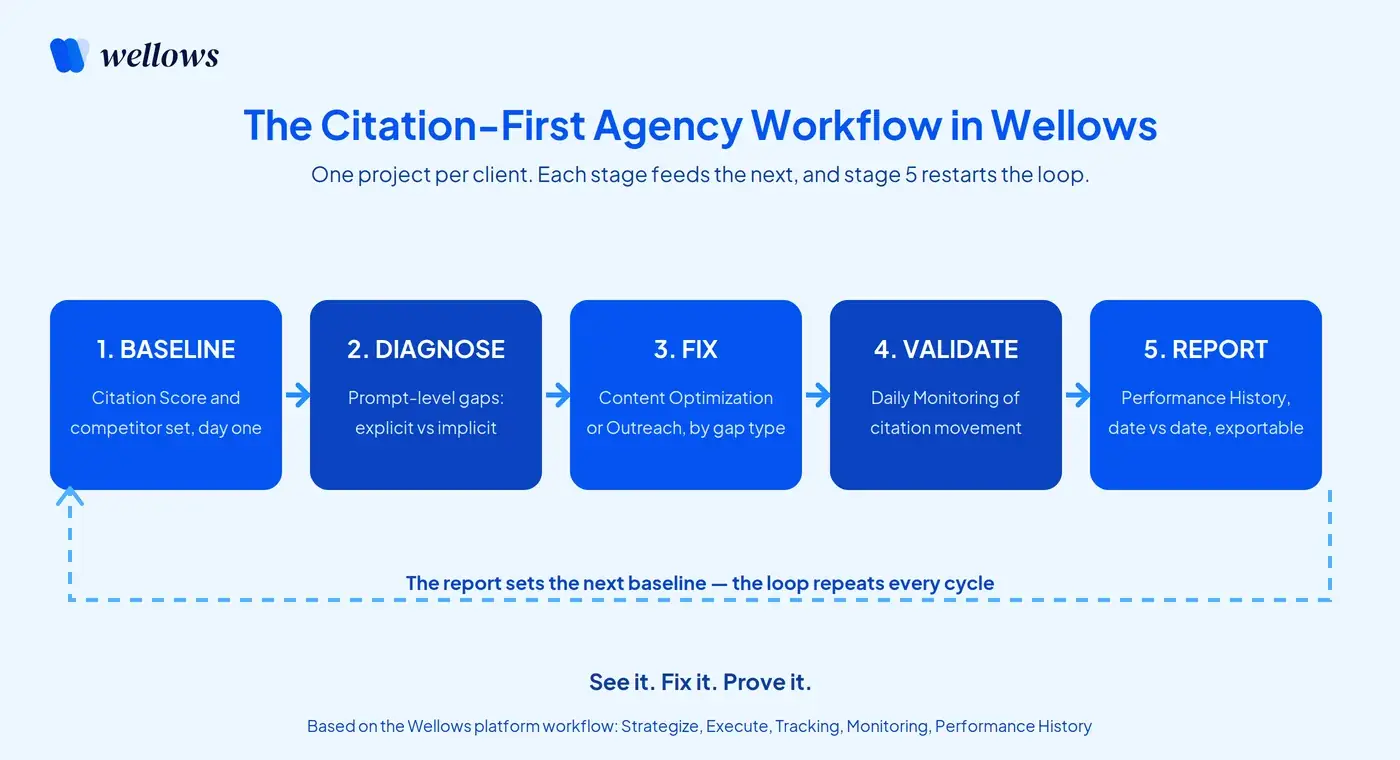
Wellows Agency Flow
Stage 1 — Baseline
Find out where the client stands before touching anything. The AI Visibility Score turns verified citations from all five engines into one benchmarkable number, alongside the competitor set Wellows maps on setup.
Prompt generation can run from the client’s own Google Search Console queries or from AI-powered suggestions based on their site and industry, so the tracked set reflects real buyer language rather than a keyword export. That first number is the baseline every later report is measured against.
Stage 2 — Diagnose
Work out where the gaps are, prompt by prompt. Prompt Tracking monitors every tracked prompt daily across ChatGPT, Google AI Overviews, Google AI Mode, Perplexity, and Gemini, flagging each response as Brand Mentioned or Not Mentioned and capturing the exact citation URLs behind it.
Filters by topic, intent, sentiment, and mention type narrow the list to the commercial prompts worth fighting for, and the LLM Visibility view shows how each engine treats the brand separately, which is where the engine-to-engine disagreement becomes visible.
Stage 3 — Fix
Close the gaps you diagnosed, with each gap type routed to the right workflow. Explicit gaps go to Content Optimization, which scans the client’s whole domain before recommending anything, checks for cannibalization, selects the single best page per prompt, and produces section-by-section gap analysis reverse-engineered from the 20 to 50 URLs the engines are currently citing for that prompt.
If no suitable page exists, it routes the prompt to new content instead of forcing an edit that won’t land.
Implicit gaps route the other direction. The third-party pages an engine cited become the outreach pipeline, with the target site already identified, so the work is earning inclusion on a source the model already trusts rather than guessing where to pitch.
Stage 4 — Validate
Confirm the work actually moved something. Daily monitoring tracks movement in explicit and implicit citations, brand-versus-competitor position by topic, and sentiment, so you can see whether citation share is rising on the prompts you touched rather than assuming the fix worked.
This is the step that turns “we did some work” into “citation share on these prompts went up.”
Stage 5 — Report
Package the proof for the client. Performance History compares any two dates and shows which citations are new and which were lost, prompt by prompt, with CSV export for client decks.
The activity log timestamps every action taken in the workspace, which doubles as the proof-of-work record for the “what did you actually do this month” conversation. The report then sets the next baseline, and the loop starts again.
The Client Deliverables That Make the Retainer Defensible
Agencies don’t lose GEO retainers because the work is bad. They lose them because the deliverables were never defined, so the client can’t tell activity from progress.
This is the deliverable set that holds up, and every item is something the workflow above produces rather than a document someone has to assemble by hand.
- AI Visibility Baseline. Day-zero Citation Score, competitor benchmark, and the full tracked prompt set by topic and intent. This is the document every later report points back to.
- Explicit citation report. The citations earned from the client’s own domain, with URLs. Verifiable, not summarized.
- Implicit citation report. The third-party pages engines cited, which doubles as the outreach pipeline with named targets.
- “Brand not mentioned” gap list. The prompts where engines answered the client’s category question without them, ranked by intent. This is next quarter’s content plan, pre-justified.
- Trend report. Date-versus-date citation movement from Performance History: what’s new, what was lost, and how the score moved against competitors.
- Proof-of-work log. Timestamped actions from the activity log, so the retainer conversation is about results, not trust.
On cadence: monitor daily in the background, report citation share weekly, and review sentiment and competitor gaps monthly.
The before/after delta around each campaign is the cleanest proof of impact an agency can put in a deck, because both numbers come from the same tracked prompt set measured the same way.
Red Flags When Evaluating AI Visibility Tools
The tooling category is crowded, and the differences are methodological rather than cosmetic. We’ve published a full comparison of AI visibility tools; whichever direction you go, these five patterns predict a tool that will produce reports your clients eventually see through.
Five red flags in AI visibility tooling
1. Mention-only scoring
2. Single-engine coverage
3. No baseline mechanics
4. Measurement with no execution layer
5. Rankings-style guarantees
How to Start Without a Budget Line
Most agencies don’t need permission to start; they need a baseline read they can show a client this week. Three free Wellows tools cover the major surfaces without a signup:
- The AI Overviews tracker shows whether a client appears in Google’s AI Overviews for their category questions.
- The ChatGPT visibility tracker does the same for ChatGPT, where citation behavior shifted fastest in our Q1 data.
- The Perplexity visibility tracker covers the engine most aggressive about live web retrieval and explicit sourcing.
Run a top client’s domain through all three. If the picture is uneven across engines, and in our experience it almost always is, you have the opening slide of the pitch, and the case for tracking it properly makes itself.
FAQs
Conclusion
The agencies that keep their clients through this shift won’t be the ones with the best opinions about AI search. They’ll be the ones who can answer “are we showing up in AI?” with a number, a trend line, and a competitor benchmark, and who can point at the specific citations behind all three.
The data says the game is winnable: citations spread across a long tail, third-party sources carry most of the weight, and roughly five slots per answer are up for grabs on every prompt that matters.
What separates a defensible AI visibility service from reporting theater is the measurement layer underneath it. Score citations. Split explicit from implicit. Baseline first, report rates, and log the work.
Three things worth doing this week: run a top client through the free trackers above, pull their 20 highest-intent buyer prompts and check who gets cited today, and set a baseline Citation Score before anyone touches a page. From there, the workflow runs on a loop, and the question your clients ask about AI stops being one you dread.


![AI Visibility for B2B Marketing Agencies: The Shortlist-Defense Playbook [2026]](https://wellows.com/wp-content/uploads/2026/06/ai-visibility-b2b-marketing-agencies.webp)

