For most agency client reports, AI visibility is summarized as a single rising or falling number. Mentions are up across ChatGPT and Perplexity. The dashboard celebrates. Then the client asks the obvious question: what did we do to make that happen?
That question is the problem with monitoring mentions in AI search visibility the way most platforms currently teach it. This post lays out a practitioner-grade alternative — what agencies should monitor, what to measure alongside mentions, and which metrics translate into a defensible client report.
Why mention-only monitoring breaks for agencies
A brand mention in an AI response is the outcome of a process the LLM ran internally. The model pulled from sources, weighted them, and decided whose name to name. By the time the mention appears on a dashboard, the work that produced it happened upstream, somewhere the agency team can’t see and didn’t touch.
That’s fine for a brand monitoring its own awareness. It’s a problem for an agency monitoring AI visibility across multiple clients, because three things drift constantly.
The model retrains, and the number moves without anyone doing anything. A prompt gets rephrased — “best CRM for startups” becomes “top CRMs for early-stage companies” — and the answer set shifts. A competitor seeds a Reddit thread or buys an industry-roundup placement, and a client’s mention rate dips through no fault of the agency.
This volatility isn’t theoretical. Profound, the market leader most agencies benchmark against, scores visibility roughly as brand mentions ÷ total category mentions × 100. Peec AI, Otterly, Ahrefs Brand Radar, and SE Ranking’s Visible follow the same model: count every time the brand name appears in a response, divide by competitor total, return a share-of-voice number.
It’s a clean number. It just isn’t a number an agency can hand a client and say: here’s what we did to move it.
“A lot of people only watch mentions and it becomes daily noise. The thing you can actually review, fix, and iterate on is usually citations.” — r/webmarketing thread
The community has noticed. LSEO published a piece arguing citation share is the only metric tied to actual commercial outcome. Passionfruit SEO ran a critique titled Why AI citations might not be the best visibility metric; that argument was different (the piece argued agencies need both layers), but the fact that the debate is live tells you the category is openly questioning mention-only scoring.
The question for an agency isn’t should I monitor mentions. The question is: what gets monitored alongside them so the report comes with an action plan attached?
Citation + mention: the two-layer monitoring methodology
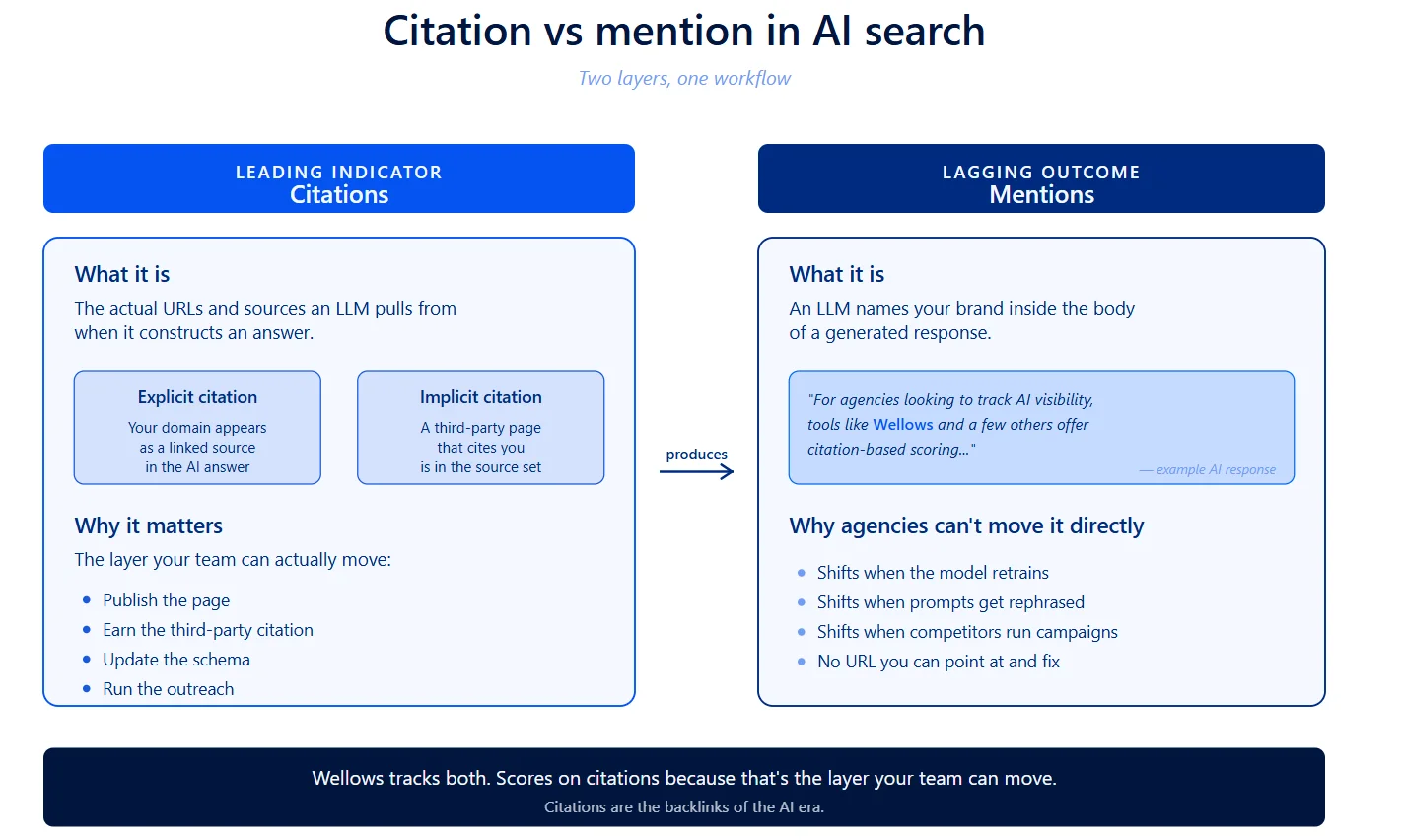
Citation vs Mentions: the two layers Wellows tracks separately
The Wellows methodology splits AI search visibility into two layers and tracks them as separate first-class metrics.
Mentions
A mention is when an LLM names a brand in the body of a response. It’s the surface read, useful for sentiment, share-of-voice narrative, and competitive context. A mention can’t be directly caused; only the conditions that lead to one can be.
Citations
A citation is the actual URL or source the LLM pulled from to construct the response. Wellows splits these further into Explicit (Content) Opportunities (the brand’s own domain appears as a linked source) and Implicit Citation Opportunities (a third-party page that already cites the brand appears as a source, and the brand inherits some of that authority). Citations are what the team can go fix, build, or earn.
Here’s why this matters operationally. If a brand isn’t in the source set, it won’t be in the answer consistently. Mentions without citations are noise: the model named the brand once because of training data, and may not name it next month.
Explicit vs Implicit citation split observed across Tracked Prompts in a representative Wellows project
In the audited project, the Citation Distribution widget showed 847 explicit citations (78.64%) against 230 implicit ones (21.36%) across all Tracked Prompts. Note: Citation Distribution counts the raw citations across tracked prompts, while Citation Score is the derived share-of-citations metric Wellows reports alongside it. Explicit and implicit citations are separated as first-class metrics across the platform, not collapsed into a single mention number, because each layer points at a different agency workflow. Explicit citations point at the client’s own domain. Implicit citations point at third-party pages already trusted by the LLM, which is where most outreach leverage lives.
Source: Wellows product audit, Tracked Prompts viewA useful way to think about it: citations are the backlinks of the AI era. Backlinks were the leading indicator for Google rankings for twenty years. Citations — explicit URLs, plus implicit third-party sources, plus forum threads, plus reviews — are the same for AI search. They’re the lever. Mentions are the read on whether the lever is working. The mechanics of LLM citation tracking — how AI systems decide which sources to reference — explain why this layer functions as the AI-era equivalent of backlinks.
Wellows monitors both layers and shows them next to each other on the same screen. But it scores on the citation layer, because that’s the one an agency team can hand a client and say: here are the URLs earned this month.
The agency monitoring workflow inside Wellows
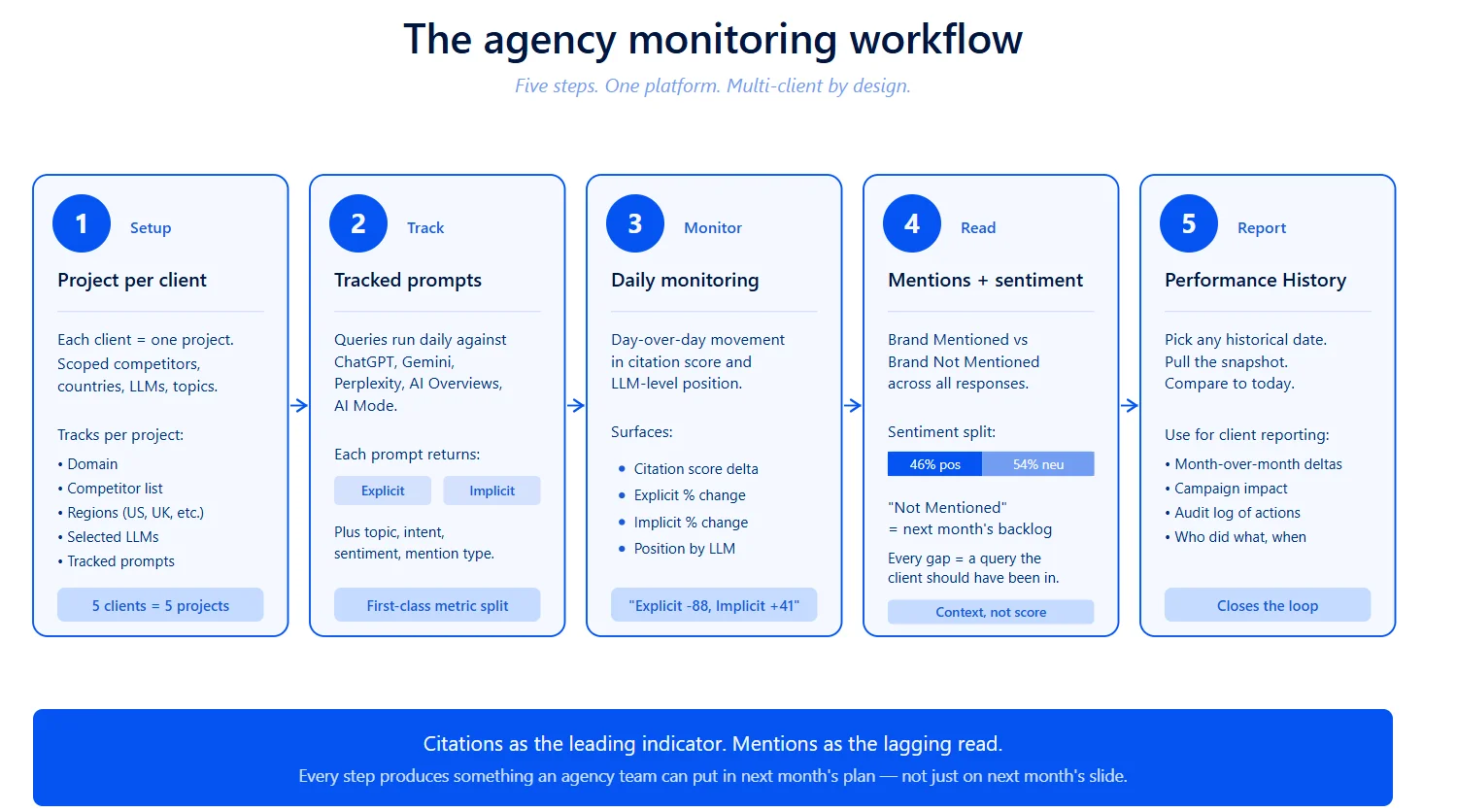
The workflow for multi-client agency setups follows five steps, none of which require leaving the platform.
1. One workspace per client, shared dashboard logic
Wellows organizes work into projects. Each project is a tracked brand plus its domain, competitors, countries, Answer Engines, and topics. An agency with five clients sets up five projects, switchable from the sidebar. Every project carries its own set of Prompts Tracked, its own competitor list, and its own monitoring cadence. Per-country competitor management is configurable independently — competitors in the US can differ from those in the UK or Canada inside the same project.
Why it matters: client A’s competitors aren’t client B’s. Client A might track ChatGPT and Perplexity in the US; client B might need Gemini and AI Overviews in the UK. Project-level scoping means filters don’t need retuning every time a report is opened.
2. Tracked prompts, with explicit and implicit split
Inside each project, the Tracked Prompts view runs the queries you care about against the Answer Engines you’ve selected, on a Daily Monitoring cadence. The table shows prompt text, topic, intent (informational, commercial, navigational, transactional), mention type (explicit/implicit), and citation count.
The split between explicit and implicit mentions is what most monitoring tools collapse into a single number. Wellows separates them, so when reviewing a client’s monitor, the agency sees at a glance which citations came from the client’s own domain and which came from third-party pages.
That separation is what makes the report actionable. Explicit (Content) Opportunities point at content the client owns or could own. Implicit Citation Opportunities point at outreach: third-party pages already cited by the LLM where a brand mention could be placed. Earning placement on those third-party pages is a digital PR motion for generative engine visibility — securing coverage on the authoritative sites LLMs already pull from.
3. Daily monitoring of citation movement
The Monitoring section runs daily and surfaces:
- Daily increases and decreases in Citation Score
- Percentage changes in Explicit (Content) Opportunities
- Percentage changes in Implicit Citation Opportunities
- Your brand’s position within Answer Engines based on tracked queries
- A quick summary of key changes, for example “Explicit -88, Implicit +41” on a given day
This is typically the first screen agencies open on a client call. Not because daily numbers matter individually (they don’t, day-over-day noise is real) but because the trend tells you whether the work is landing. If implicit citations are up 41 in a week, that’s outreach paying off. If explicit citations are down 88, something happened to a page or a model run that needs investigation. For agencies that want to push beyond manual daily checks, real time alerts for agency clients flag material movement before the next standing call.
4. Sentiment and brand mention ratio, side by side
Mentions still belong in the monitor, just not as the scoring layer. Wellows surfaces them as a context read: Brand Mentioned versus Brand Not Mentioned across all tracked responses, broken out by Brand Sentiment Analysis. In a representative project, the AI Responses tab showed 686 responses with the brand mentioned against 4,070 where it wasn’t, with sentiment skewing positive.
Sentiment itself is reported as a percentage of all mentions across LLMs, broken into Positive (favorable descriptions), Neutral (informational or non-opinionated), and Negative (complaints, concerns, or negative framing). The headline isn’t that AI search is friendly to brands; it’s that when a brand is cited, sentiment usually skews neutral-to-positive. The real fight is getting cited in the first place.
The “Brand Not Mentioned” count is one of the most useful numbers in the product. It’s the gap. Every prompt in that bucket is a query where the client should have been in the answer and wasn’t. That’s next month’s content backlog, sitting right there. For agencies looking to work through those gaps systematically, finding hidden AI visibility gaps for clients walks through the audit workflow query by query.
5. Performance History for the client report
The Performance History section lets you pick any historical date and pull the exact snapshot — Brand Visibility Score, citation count, prompt-level performance — for that date. For agencies reporting monthly, this is the screen that closes the loop. Compare last month’s snapshot to this month’s, isolate the deltas, and walk the client through what moved.
Your Activity (the audit log) sits next to it: every Content Generation event, every outreach action, with status and timestamp and the team member responsible. Agencies need this for two reasons: internal QA, and client transparency. A monthly report that says “we did X, Y, Z, and here’s what moved” reads completely differently to a client than “your visibility score went up.” A full breakdown of how to structure these monthly deliverables sits in agency reporting for AI search.
How Wellows compares to mention-only monitoring tools
Most AI visibility tools converge on a single mention-share number. The differences are real but easy to miss in a demo. Here’s how the methodology stacks up:
| Tool | Scoring methodology | Citation tracking | Agency workflow |
|---|---|---|---|
| Wellows | Explicit + implicit citation share | Yes — explicit URLs and implicit sources tracked separately | Multi-project, audit log, outreach + content opportunities built in |
| Profound | Mention share (brand mentions ÷ total category mentions) | Citation tab available, but not the scoring layer | Enterprise/Agency plans with dedicated GEO strategist |
| Peec AI | Mention share | Limited | Agency Partner Program with co-marketing |
| Otterly | Mention share | Limited | Not publicly described |
None of this means Profound or Peec are wrong. They measure something real, and category-level mention data has legitimate uses for board-level reporting. The argument is narrower: when the job is to move the number for a client this quarter, the layer that gets monitored has to be the layer the team can touch. Citations are that layer.
What to change about how most agencies report AI search visibility
✕ What most agencies do today
Report a single AI visibility score (usually mention-based), trend it month over month, attach a screenshot of the dashboard. The client sees a number go up or down. Nobody on the team can confidently explain why.
✓ What the client report should include instead
Three rows: explicit citations earned this period (with URLs), implicit citations earned (with the third-party pages), and “brand not mentioned” gaps with the top queries to address next month. The cover-slide number can still be Brand Visibility Score, but every page after it should be the leading indicators that produced it.
The shift is small. The client conversation it produces is completely different.
A metric a team can’t move is a vanity metric. A monitoring system that only tracks the outcome, without tracking the inputs that can be fixed, is one a client will eventually push back on. Probably this quarter.
Pulling it together
Monitoring mentions in AI search is necessary. It’s a read on whether the work is landing. But for agencies, monitoring only mentions leaves you reporting a number whose movements you can’t explain or reproduce.
The two-layer methodology, citation as the leading indicator and mention as the lagging read, is what makes the monitor actionable. Wellows tracks both, surfaces them on the same screens, and scores on the layer where the agency team has actual leverage. For agencies running multiple clients, that’s the difference between a report that ends in a question and a report that ends in next month’s plan.
Related Articles
- How Agencies can Find Hidden Visibility Gaps for Clients
- How Agencies Can Onboard New Clients Faster Using AI Search Visibility Platforms
- Social media marketing agencies
- Generative Engine Optimization Agencies
- Digital marketing agencies
- Content marketing agencies
A mention is when an LLM names a brand inside the response text, surface-level visibility. A citation is the actual URL or source the LLM pulled from to construct that response. Wellows further splits citations into explicit (the brand’s own domain cited) and implicit (a third-party page that cites the brand appears as a source). Mentions tell you whether the brand is being seen; citations tell you why, and which assets to build next.
Wellows runs Daily Monitoring across Prompts Tracked and surfaces day-over-day movement in Citation Score, Explicit (Content) Opportunities, Implicit Citation Opportunities, and Answer-Engine-level position. The Performance History view lets you pick any historical date and pull the snapshot, so you can compare month-over-month or campaign-over-campaign deltas for client reporting.
Yes. Each tracked brand sits in its own project, with its own competitors, countries, Answer Engines, topics, and Prompts Tracked. You switch between projects from the sidebar, and Your Activity gives you a full audit log per project, which agencies use for client transparency and internal QA.
Yes. Mentions appear throughout the platform: Brand Sentiment Analysis, Brand Mentioned versus Brand Not Mentioned counts, mention-type filters on Tracked Prompts. The methodological choice is what gets scored: Wellows scores on Explicit (Content) and Implicit Citation Opportunities because that’s the layer the team can move. Mentions are still tracked, surfaced, and reported on alongside.
Wellows monitors ChatGPT, Gemini, Perplexity, AI Overviews, and AI Mode. You select which subset to track per project, and Daily Monitoring reports Citation Score per Answer Engine individually as well as in aggregate.


![AI Visibility for B2B Marketing Agencies: The Shortlist-Defense Playbook [2026]](https://wellows.com/wp-content/uploads/2026/06/ai-visibility-b2b-marketing-agencies.webp)

