Brand visibility in LLMs is how often, how accurately, and how prominently AI systems like ChatGPT, Gemini, and Perplexity mention a brand in their answers. Unlike traditional SEO, success is measured through citations, mentions, sentiment, and share of voice, not rankings. Because the sources AI cites change ~65% every two weeks, auditing must be continuous.
When was the last time you asked ChatGPT, Gemini, or Perplexity about a brand, maybe even your own? The way these models describe your company now shapes how customers, investors, and competitors perceive you, often before anyone visits your site, and most brands have no idea what that description says.
The numbers explain why that blind spot is expensive. In Wellows’ analysis of 11.1 million AI citations, only 6.8% of cited sources carry any brand mention, and two-thirds of answers name no brand at all. The sources an engine cites also churn ~65% in two weeks.
AI assistants are now part of how people research purchases, with a Salesforce survey finding a majority consult them before buying. Being absent or misdescribed has a direct cost, which is why a one-time check isn’t enough and a real audit is.
This guide explains what brand visibility in LLMs is, what influences it, how to audit it, and how to improve it, using data from 11.1 million AI citations.
- Brand visibility in LLMs is how often, how accurately, and how favorably ChatGPT, Gemini, and Perplexity name your brand. It’s the new zero-click SEO.
- You don’t rank, you get mentioned and cited. Only 6.8% of sources carry a brand mention, and brands are named in text about 8x more often than they’re linked.
- Two-thirds of AI answers name no brand at all, so the space is wide open for brands that audit and act.
- It runs on three levers: semantic, structured content; third-party validation (Reddit, reviews, publications); and consistent terminology across the web.
- Visibility is fragmented: the engines agree on under 5% of sources, so audit per engine, not once.
- Visibility is volatile: ~65% of cited sources change within two weeks, so auditing is continuous, not one-and-done.
- A real audit tracks mentions, sentiment, accuracy, and share of voice, then re-checks on a schedule.
What Does Brand Visibility Mean in the Context of LLMs?
Brand visibility in LLMs
Brand visibility in LLMs is how often, how accurately, and how favorably models like ChatGPT, Gemini, and Perplexity reference your brand when users ask relevant questions. The measurable unit is the mention or citation inside an answer, not a rank. It’s the modern equivalent of zero-click SEO: you win the answer, not the ranking.
Because LLMs generate direct responses rather than ranked links, visibility depends on whether the model understands your entity, trusts its sources, and frames your brand correctly. This shift is why the discipline is grouped with GEO and tracked through brand performance metrics in AI search.
What Influences Brand Visibility in LLMs?
Brand visibility in LLMs is driven by ten factors, and they sort cleanly under the three levers an audit checks. Knowing which factor is weak tells you exactly what to fix.
Content and structure signals
- Content structure: answer-first passages an engine can lift cleanly, the format behind ~45% of citations (how-to and product pages).
- Structured data: schema that labels your questions, answers, and entities so models parse you correctly.
- Entity recognition: whether AI correctly identifies who you are and what you do, without confusing you for a similarly named company.
- Consistent brand terminology: the same name, category, and product language everywhere, so your entity doesn’t fragment.
Validation and authority signals
- Third-party mentions: corroboration on sites AI trusts, the consensus signal models weigh heavily.
- Citation frequency: how often you’re actually pulled into answers across your target prompts.
- Source authority: the quality of domains citing you, though relevance often beats raw DA (38% of cited sources are under DA 30).
- User-generated content: Reddit, Quora, and YouTube threads, which together out-cite any single publisher category.
- Review platforms: rating sites and directories that confirm you exist and are credible.
- Digital PR: earned coverage in publications that feed the model fresh, authoritative references.
The pattern: the first four are things you control on your own site, the last six are earned off it. A brand visibility audit measures both, because a page can be perfectly structured and still invisible if no trusted third party corroborates it.
Brand Visibility vs Brand Awareness in LLMs
Visibility and awareness are easy to confuse but measure different things. Visibility is whether AI surfaces your brand inside an answer; awareness is whether users recognize it once they see it. The table makes the split concrete:
| Dimension | Brand Visibility | Brand Awareness |
|---|---|---|
| What it measures | Mentions inside AI answers | Recognition and recall by people |
| AI focus | Citations and source inclusion | Familiarity once encountered |
| Primary KPI | Share of voice | Brand recall and sentiment |
| What it creates | Presence and opportunity | Trust and preference |
| Impact on GEO | High, it’s the direct lever | Medium, it reinforces over time |
In LLM-driven discovery, visibility gets you into the answer and awareness shapes how that mention lands. You need both: discoverable within AI systems, and correctly understood by the people who rely on them.
What Does AI Actually Think Your Brand Does?
Before an engine cites you, it forms a working model of what your brand is and who it serves, assembled from your site, reviews, directories, forums, and news. Auditing starts with reading that model back, because if AI misunderstands your category, no ranking fixes it. The fastest way is to ask the engines directly.
✕ What you see in the audit
You ask ChatGPT, Gemini, and Perplexity “What is [Brand] and who is it for?” One calls you a generalist, one omits your flagship product, and one confuses you with a similarly named company. That divergence is the finding: AI’s model of your brand is inconsistent and partly wrong.
✓ What it tells you to fix
Inconsistent descriptions point straight to the three levers: thin or unstructured content (semantic), missing third-party corroboration (validation), and mixed naming across profiles (terminology). You now know exactly which gap to close, rather than guessing.
Did you know?
This is why “how LLMs see your brand” is the real starting question of any audit. A mention is only useful if the surrounding description is accurate, on-category, and framed the way you’d frame yourself.
What the Data Says About Auditing Brand Visibility on LLMs
Most advice on this topic is generic. To ground it, Wellows analyzed 11.1 million individual citations across 571,729 AI answers (Dec 2025–Mar 2026), spanning 363 brands and 35 regions, across ChatGPT, Gemini, Perplexity, Google AI Overviews, and Google AI Mode. Five findings directly shape how you should run an LLM visibility audit.
Study methodology
- Dataset: 571,729 AI answers, 11.1 million individual citations
- Engines: ChatGPT, Gemini, Perplexity, Google AI Overviews, Google AI Mode
- Collection period: December 2025 – March 2026
- Coverage: 363 brands across 35 regions, 35,404 distinct queries
- Scope note: tracked-brand data skews toward VPN/cybersecurity and martech (US and India); structural findings generalize, specific domain rankings reflect the brands tracked
Share of cited sources that stay the same when the same query is re-asked two weeks later
Roughly two-thirds of cited sources churn between observations. A one-time visibility audit is out of date almost immediately, which is the strongest argument for continuous monitoring over an annual check. This is why auditing at scale across ChatGPT, Gemini, and other LLMs is really a question of cadence, not a one-off scan.
Source: Wellows analysis of 11.1M AI citations, Dec 2025 - Mar 2026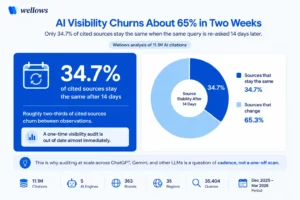
Visibility varies by engine, so audit all of them
The same brand can be visible in one engine and invisible in another, which is why measuring brand presence in AI chatbots like ChatGPT and Gemini has to be done per platform.
ChatGPT carries a brand mention in 7.6% of its citations and names brands explicitly in 2.4%, while Perplexity is the stingiest on explicit mentions at just 1.5% (AI Overviews 6.5%, Gemini and AI Mode 6.3% sit between). ChatGPT explicitly names brands about 65% more often than Perplexity, so a single-engine audit distorts the picture.
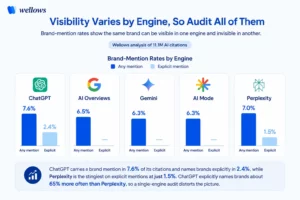
The practical upshot: each engine leans on different sources and names brands at different rates, so the same audit prompt can show you winning in one and absent in another. The table below maps what each engine rewards and the move that wins it.
| Engine | Any-mention rate | What it leans on | The audit move that wins it |
|---|---|---|---|
| ChatGPT | 7.6% (2.4% explicit, the highest) | Bing index, plus directories and well-structured pages | Confirm Bing indexing, fix directory listings, publish answer-first pages |
| Google AI Overviews | 6.5% | The organic index, closely tied to existing rankings | Keep strong traditional SEO on your priority pages |
| Gemini | 6.3% | Google ecosystem and Maps-grounded local data | Perfect entity data, schema, and Google Business Profile |
| Google AI Mode | 6.3% | Google index with broader query fan-out | Cover related sub-questions, not just the head query |
| Perplexity | 7.0% any, but only 1.5% explicit | Live web across many sources, heavily Reddit and fresh content | Earn forum and review presence; publish dated, current pages |
- The first five sources are the whole game. 98.8% of all citations sit in positions 1–5 of an AI answer, and brand-mention rates peak in the top two slots. There is no “page two” in AI search, so your audit must record not just whether you appear, but where.
- Share of voice is winner-take-most. The single most-visible brand in a topic captures about 37% of all mentions (median ~21%), yet an average of 48 distinct brands compete for the rest. The gap between the leader and everyone else is the thing an audit should measure.
- Authority helps, but it isn’t everything. The average DA of a cited source is 42.9, and while 1 in 5 is DA 70+, fully 38% are under DA 30. Relevance and specificity beat raw authority for a huge share of placements, so smaller brands can and do get cited.
- Sentiment is mostly positive. When a brand is named, the tone is positive ~70% of the time, neutral ~27%, negative ~3%. The rare negative cases are exactly what an audit should catch, because they’re high-impact.
Methodology note: figures reflect Wellows’ tracked-brand dataset (skewed toward VPN/cybersecurity and martech, US and India). Treat specific domain rankings as “across the brands we track.” The structural findings, volatility, per-engine variance, position concentration, share-of-voice, and authority distribution, generalize well.
Why Does My Brand Appear in ChatGPT but Not Perplexity?
Because each engine builds answers from a different source pool, and your brand is well-represented in one but thin in another. This is the most common question in brand-visibility auditing, and the answer is mechanical: ChatGPT, Gemini, Perplexity, and Claude reward different signals, so one can cite you confidently while the next ignores you.
| Engine | What drives visibility | You’re likely strong here if… |
|---|---|---|
| ChatGPT | Bing index, directories, and well-structured content | You’re indexed in Bing, have clean directory listings, and publish answer-first pages |
| Gemini | Google ecosystem and entity signals, grounded in Maps data | Your entity, schema, and Google Business Profile are accurate and consistent |
| Perplexity | Live web and fresh citations, heavily Reddit and forums | You have recent third-party mentions and genuine community presence |
| Claude | Authority and explanatory, well-sourced content | Your content is in-depth, factual, and corroborated by trusted sources |
Read the pattern in your own audit and the diagnosis falls out:
- Visible in ChatGPT, absent in Perplexity? Your owned content and directory presence are solid, but you lack the fresh, third-party and community signals Perplexity leans on. The fix is off-site: earn recent mentions, reviews, and genuine Reddit or forum presence, exactly the kind of offsite footprint analysis behind “how do I analyze my brand’s offsite presence in LLM responses.”
- Visible in Perplexity, absent in ChatGPT? You have web buzz but weak structured fundamentals. Confirm Bing indexing, clean up directory listings, and tighten your schema.
- Strong in Gemini, weak elsewhere? Your Google entity is healthy but isn’t corroborated widely enough. Build the broader third-party validation the other engines need.
This is exactly why a single-engine check misleads you, and why a proper audit covers 2–3 engines and reads each separately. A fix for Gemini is not a fix for Perplexity, and an engine you’re strong in does not predict the one you’re weak in. Plan the work per platform, not per brand.
How Do You Improve Brand Visibility Inside LLMs? (The 3 Levers)
Optimizing for brand visibility requires a different strategy from traditional search. Three levers drive whether AI engines surface your brand, and a good audit checks all three.
The Three Levers of LLM Brand Visibility
1. Semantic, Structured Content
2. Third-Party Validation
3. Consistent Terminology
Because visibility is fragmented across platforms and changes constantly, these levers are checked through structured, repeatable monitoring rather than a single manual sweep.
How Do I Check If My Brand Shows Up in ChatGPT?
The fastest check is to ask the engines directly. Open ChatGPT, Gemini, and Perplexity and run a handful of natural prompts the way a real prospect would, then read whether your brand appears, how it’s described, and who shows up instead.
- “What is [Brand]?” and “Is [Brand] good for [use case]?”
- “Best [product or service] providers” (no brand named, to test organic visibility)
- “[Brand] vs [Competitor]” and “alternatives to [Competitor]”
- “Which companies offer [service]?”
Run each prompt two or three times, because answers shift between runs, and note the rate your brand appears rather than a single yes/no. The difference between a useful check and a useless one is in how you read the result:
✕ Weak check
You ask “What is [Brand]?” once, see your name appear, and conclude you’re visible. That’s a single run of a branded prompt, the easiest possible test, and it tells you nothing about non-branded discovery or consistency.
✓ Strong check
You run five non-branded prompts (“best [category] providers”) across ChatGPT, Gemini, and Perplexity, three times each, and log how often you appear, in what position, and who outranks you. Now you have a baseline you can re-measure.
Manual checks are perfect for a quick read, but they only show fragments. Because the engines agree on under 5% of sources and ~65% of citations churn in two weeks, a real answer needs the structured, repeatable audit below, run across engines and on a cadence.
Did you know?
A structured setup ensures your audit produces measurable, repeatable insights rather than scattered observations.
How Should You Prepare for a Brand Visibility Audit?
1. Define Your Objectives
2. Select Priority Engines
3. Build a Keyword & Prompt List
4. Set Up a Recording Sheet
What Steps Should You Follow to Audit Brand Visibility on LLMs?
Conducting an audit doesn’t have to be complicated, but it should be systematic. When agencies audit brand visibility on LLMs, this structured process shows where they stand today, how AI describes them, and what to fix next.
- Step 1: Run basic prompts: Start with the obvious: “What is [Brand]?”, “Is [Brand] reliable?”, “[Brand] vs [Competitor]”. This baselines whether your brand appears at all and how prominently.
- Step 2: Run advanced prompts: Test broader, non-branded contexts: “Best solutions for [pain point]”, “Top providers in [industry]”. These reveal whether you surface organically when users don’t name you, which is where most discovery happens.
- Step 3: Analyze sources: Identify where the information comes from, Wikipedia, directories, review sites, news, your own pages, and reinforce them with structured data. Because ~38% of cited sources are under DA 30, relevant niche sources matter as much as big-authority ones.
- Step 4: Audit your website and content structure: Check schema markup (FAQ, Product, Article), clear factual pages (About, Team, Product), updated FAQs, and consistent brand terms, using an on-page content checklist. Well-structured content increases the chance LLMs reference you correctly.
- Step 5: Measure sentiment and accuracy: Note the tone (positive, neutral, negative) and whether the facts are current. Since brands are described positively ~70% of the time in our data, a negative rate much above ~3% is a red flag worth catching early.
- Step 6: Benchmark against competitors: Run the same prompts for 2–3 competitors and record mention frequency, source quality, sentiment, and accuracy. Since one brand often owns ~37% of mentions in a topic, benchmarking tells you whether you’re the leader or among the ~48 chasing.
- Step 7: Document findings and set a re-audit routine: Log results with columns for prompt, platform, response summary, position, visibility score, and sentiment. Because ~65% of sources churn in two weeks, schedule monthly or quarterly re-audits to catch shifts before they become gaps.
A worked example. Say you run 20 category prompts across three engines and log every brand named. Your brand appears in 6, a top competitor in 13. Your raw mention frequency is 30%, but your share of voice against that competitor is 6 to 13, you’re being out-cited better than 2 to 1.
That reframes the problem as competitive, not absolute. Step 3 tells you why: pull the 13 answers where they won and check which sources fed them. If the same three review sites and one Reddit thread keep appearing, that is your validation gap, named and actionable.
What Metrics Should You Track During an LLM Audit?
It’s not enough to note whether your name appears. Track these to see how often you’re mentioned, how you’re framed, and how you compare, the same indicators covered in LLM SEO.
1. Brand Mention Frequency
How often your brand appears across all tested prompts. Example: 8 of 20 prompts → 40% mention frequency. Track per engine, since rates vary widely (ChatGPT 2.4% vs Perplexity 1.5% explicit).2. Sentiment Split
Categorize mentions as positive, neutral, or negative. As a benchmark, our data shows ~70% positive / 27% neutral / 3% negative across brands, so a negative rate well above that is a flag worth investigating.3. Response Position
Where you appear matters: a top-five mention carries authority, a buried one has little influence, and exclusion is a visibility gap. With 98.8% of citations in positions 1–5, anything lower barely registers.4. Source Diversity and Authority
How many distinct sources cite you, and how authoritative they are. Mix matters: chase relevant niche sources too, not just DA 70+ domains, since ~38% of cited sources are under DA 30.5. Share of Voice vs Competitors
Your slice of brand mentions in a topic versus rivals. This is the headline number, the gap between the ~37% leader and everyone else is what an audit exists to close.Can I See How Often My Company Is Mentioned in AI Responses?
Yes. Manual checks inside ChatGPT, Gemini, or Perplexity reveal isolated moments, but auditing at scale means tracking two things: explicit mentions (your brand named directly) and implicit mentions (your category described without naming you). Because brands are named about 8x more often than they’re linked, most real visibility is implicit.
Wellows tracks both at once across ChatGPT, Gemini, Perplexity, AI Overviews, and AI Mode, surfacing citation scores, sentiment, competitor share of voice, and historical trends from one dashboard. That turns the manual spot-check into the continuous, multi-engine audit the data demands.
What Are the Common Pitfalls in Auditing Brand Visibility?
Even a well-planned audit falls short if you overlook these:
✕ Only testing one engine
Auditing a single model gives an incomplete view, and mention rates vary widely (ChatGPT names brands explicitly ~65% more than Perplexity), so one engine distorts your picture.
✓ The fix
Audit 2–3 engines that matter to your audience and report each separately, because a fix for Gemini is not a fix for Perplexity.
✕ Auditing once
With ~65% of cited sources churning within two weeks, a single audit is stale almost immediately and tells you nothing about trend.
✓ The fix
Run on a cadence, weekly spot-checks on fast-moving engines, a deeper monthly or quarterly review, and compare against the same prompt set each time.
✕ Tracking mentions but not sentiment, position, or context
A raw mention count hides whether you’re framed positively, cited in the top five, or buried, and the rare ~3% negative mentions are high-impact.
✓ The fix
Score sentiment, response position, and competitive framing alongside frequency, so a mention becomes meaningful visibility, not just a tally.
✕ No competitor benchmark and inconsistent terminology
Without share-of-voice context you can’t measure your real position, and mixed brand descriptions split your entity and weaken recognition everywhere.
✓ The fix
Benchmark citation share against named competitors, and unify your name, category, and product terminology across site, profiles, and directories.
How Do You Improve Brand Visibility After an Audit?
An audit is only valuable if it leads to action. Once you’ve found the gaps, pair the fixes with the best AI content optimization tools to turn findings into citation-ready pages.
- Update or correct external sources. Keep directories, Wikipedia, knowledge panels, and review sites current; fix outdated product details, leadership names, or descriptions LLMs may pull in.
- Optimize on-site content. Add structured data (FAQ, Product, Article schema per Schema.org, validated with Google’s Rich Results Test), create answer-first FAQ pages, and keep About and product pages factually precise.
- Publish expert content and comparisons. Develop thought leadership and comparison guides backed by strong digital PR, covering problem-solution topics where your brand should be the answer.
- Strengthen off-site authority. Earn reviews on trusted platforms and genuine presence in relevant communities like Reddit, plus guest articles, interviews, and media mentions.
- Track improvements in recurring audits. Re-audit monthly or quarterly with consistent prompts and scoring, so you can prove share-of-voice gains over time. Wellows records this history automatically across engines.
The single biggest lever is usually the content itself, specifically, whether a page answers a real question cleanly enough for an engine to lift it. Here’s the difference in practice:
✕ Content AI skips
A page titled “Our Innovative Solutions for Modern Businesses” that opens with three paragraphs of brand mission before mentioning what the product does. There’s no extractable answer, so the engine has nothing clean to quote.
✓ Content AI cites
A page titled “How does [category] software reduce reporting time?” that opens with a direct 40-to-60-word answer, then backs it with a short list and a data point. It answers the exact question, in a liftable block, with a fact worth citing.
Case Study: How Articos Grew AI Visibility 205% in 34 Days With Wellows
A real audit-to-action example shows what these steps produce.
FAQs
Conclusion
Auditing brand visibility in LLMs is no longer a nice-to-have. As people rely on ChatGPT, Gemini, Claude, and Perplexity to shape decisions, your presence in those answers affects trust and conversions. Only 6.8% of sources carry a brand mention, two-thirds of answers name no brand, and ~65% of sources churn within two weeks.
A structured audit tells you not just if your brand appears, but how it’s represented, across mentions, sentiment, position, and share of voice. Start with simple prompts, log results, benchmark competitors, and re-check on a schedule. The sooner you begin, the sooner you claim the open space most brands are leaving behind.
Key Takeaway — Brand visibility in LLMs is the new zero-click SEO, and it’s measurable. Audit across engines, track mentions, sentiment, position, and share of voice, then re-check on a cadence. Two-thirds of AI answers still name no brand, so the space is open for whoever audits and acts first.
