Have you ever poured hours into creating thoughtful, high-quality content, only to see it completely ignored by AI? Meanwhile, your competitor’s quick, half-baked blog post is the one ChatGPT keeps referencing. It’s frustrating—and you’re not alone.
That’s why having a clear LLM Pattern Analysis Checklist is essential. Tools like ChatGPT, Google Gemini, and Microsoft Copilot don’t just help users; they decide what content gets seen.
The old SEO playbook—keywords, backlinks, metadata—is no longer enough. According to a 2025 report by Ice Nine Online, most content written for search engines never makes it into AI outputs.
Instead, large language models prioritize well-structured, semantically clear content that’s rich with recognized entities—the people, products, and topics they already know how to connect.
And it’s not just structure. Research from OpenAI and Google shows that AI looks for trust signals: real evidence, multiple viewpoints, and a tone that acknowledges nuance, not just bold declarations.
That’s why I created this guide—to show what truly matters in the age of LLMs. Getting ranked in Google is no longer the finish line. Today, your content must be clear, credible, and AI-friendly enough to be used.
One of the most effective ways to achieve that is by starting with a well-defined content brief that aligns with AI recognition patterns.

TL;DR — What You’ll Learn in This Guide
- This checklist shows how AI systems select, structure, and surface content.
- It helps you align your pages with patterns LLMs already recognize.
- You’ll learn how queries, semantics, evidence, and citations shape visibility.
- The framework lets you test content across multiple models for clearer insights.
- Use it to make your content easier for AI to understand, reuse, and reference—paired perfectly with our GEO Hub for deeper generative engine optimization.
[/engines_chart]
What Is LLM Pattern Analysis and Why Does It Matter?
LLM Pattern Analysis is reverse-engineering how AI systems select, prioritize, and present information.
While traditional SEO focuses on ranking in search results, pattern analysis focuses on getting your content featured in AI responses.

Key pattern types include:
- Query-Level Analysis — Understanding what users ask AI (very different from Google searches)
- Structure-Level Analysis — Identifying the templates AI naturally follows
- Citation-Level Analysis — Tracking which sources AI systems prefer to reference
- Format-Level Analysis — Determining what content structures get prioritized
- Semantic-Level Analysis — Mapping AI’s understanding of concept relationships
This LLM Pattern Analysis Checklist gives you a systematic approach to understanding how AI systems select, interpret, and prioritize content.
Before you jump in, think about LLM Seeding putting your best, most AI-ready content where models are most likely to “see” it, so you’re not just optimized, but also discoverable.
What are the Key Components in the LLM Pattern Analysis Checklist 2026?
To make this process easier to follow, we’ve broken it into 7 essential components. Together, they form the LLM Pattern Analysis Checklist 2026, with each stage showing how it directly supports AI visibility and overall content performance.
This aligns closely with the principles of Generative Engine Optimization (GEO), which focuses on helping content become more understandable, reusable, and surfaceable inside LLMs.
1. Foundation and Preparation
Set up the tools, frameworks, and baseline measurements needed to start your pattern analysis.
This phase focuses on building the infrastructure you’ll need and defining clear goals before diving into testing.
CHECKLIST TIP: AI Model Selection for Pattern Analysis
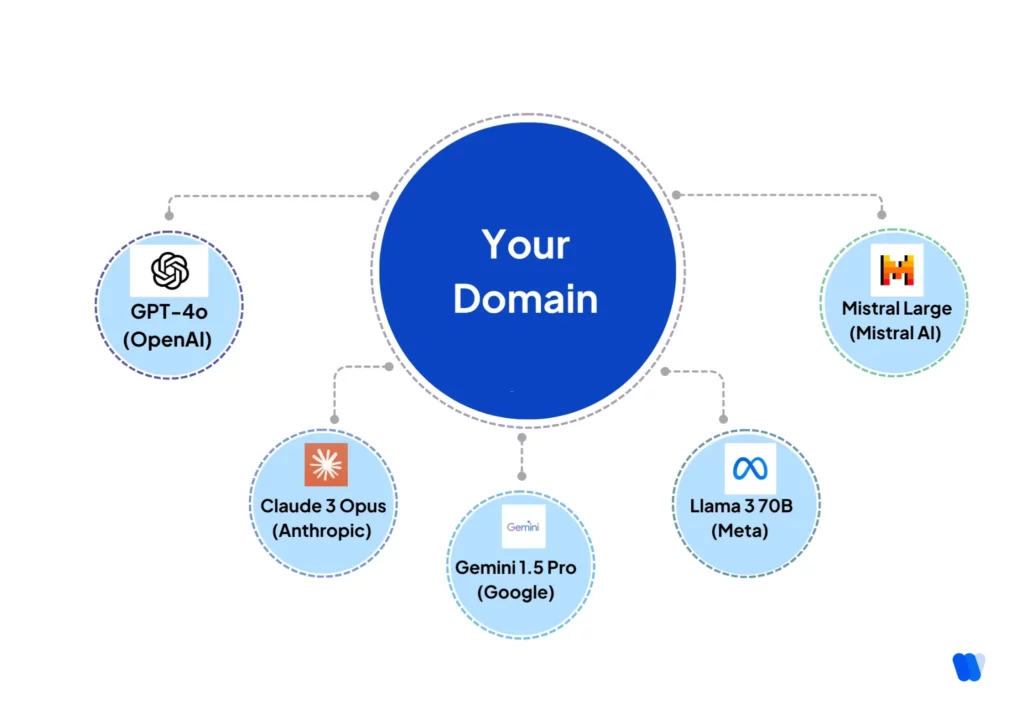
Create a diverse testing environment with these specific models that represent different training approaches:
- GPT-4o (OpenAI) – Multimodal champion with strong citation habits
- Claude 3 Opus (Anthropic) – Excels at nuanced reasoning with distinct citation patterns
- Gemini 1.5 Pro (Google) – Knowledge-dense with unique document analysis capabilities
- Llama 3 70B (Meta) – Open model with different training methodology
- Mistral Large (Mistral AI) – European model with alternative training data
Each model has distinct “citation personalities” – GPT-4o frequently references authoritative domains, Claude 3 tends to include more diverse sources, and Gemini typically cites fewer sources but with more specificity.
Perplexity, in particular, behaves more like a hybrid search engine and LLM, rewarding editorial-style analysis and structured comparisons — a pattern that becomes clearer when you study how to rank in Perplexity.
Analysis Infrastructure Setup
- Establish accounts across multiple leading LLMs (ChatGPT, Claude, Gemini, etc.)
- Set up API access for programmatic interaction with LLMs where available
- Create standardized prompt templates for consistent testing
- Develop a structured data capture system (spreadsheets or databases)
- Implement version tracking to monitor pattern changes over time
Target Definition and Scope
- Define specific content categories and topics for analysis
- Identify primary use cases and goals for pattern insights
- Determine key competitors whose content appears in AI responses
- Establish baseline metrics for current content performance with LLMs
- Set quantifiable objectives for pattern-aligned content improvements
Critical Insight:
Our comprehensive analysis of 485,000+ ChatGPT citations reveals that while the top 50 domains capture 48% of citations, 52% goes to long-tail sites, proving niche expertise can compete with authority when content directly answers specific queries.
Key Takeaway: Highly specialized content can compete effectively with broadly recognized authorities.
2. Query Pattern Discovery
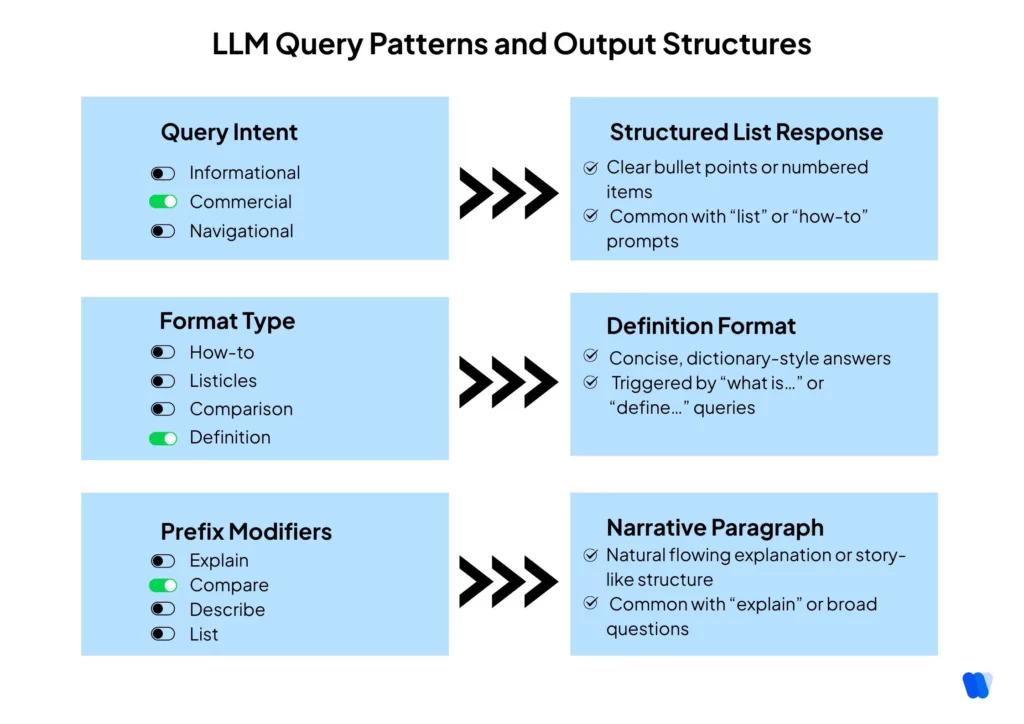
Understand how different query types and structures affect LLM responses.
This phase helps you map the questions people actually ask AI systems and how those questions shape the content that gets featured.
Seed Query Development
- Compile 10-15 core topics relevant to your content domain and generate 5-10 question variations for each core topic
- Include queries with different intent types (informational, commercial, navigational)
- Create format-specific queries (how-to, list, comparison, definition)
- Add temporal variations (current, trending, historical perspectives)
Query Transformation Techniques
- Submit identical queries across multiple LLMs to identify consistency
- Test variations in query formatting (questions vs. statements vs. commands)
- Experiment with different specificity levels (broad to highly specific)
- Test prefix modifiers (“explain,” “describe,” “compare,” “list”)
- Analyze follow-up query patterns that LLMs generate themselves
PRO TIP: The “Citation Trigger Threshold”
Every topic has what I call a “citation trigger threshold” – the level of specificity or complexity that causes LLMs to start citing sources rather than providing general knowledge answers.
Through systematic testing, I’ve found that queries at intermediate specificity (neither too broad nor too niche) typically generate the most citations.
For example:
Low citation rate: “What is blockchain?”
High citation rate: “What are the energy consumption differences between proof-of-work and proof-of-stake blockchain systems?”
Low citation rate: “What is the exact energy usage of Ethereum’s beacon chain in kilowatt-hours?”
Find your topic’s citation sweet spot by running systematic query variations. This step in the LLM Pattern Analysis Checklist helps you identify how AI models surface references and ensures your content aligns with the patterns they already recognize.
Where Can I Find Examples of Pattern Analysis Checklists Used in Marketing Analytics?
Examples of pattern analysis checklists are not always published openly, but several reputable sources share frameworks you can adapt for marketing analytics, trend detection, and AI search visibility.
- TDWI Strategic Frameworks — TDWI reports outline structured approaches for data analysis, including how teams organize insights, evaluate performance, and build systematic review processes. These frameworks can be adapted into your own pattern analysis checklist.
- Ladder’s Marketing Metrics Checklist — Ladder offers a simple, action-focused checklist that covers trend evaluation, metric comparison, and channel performance. Its structure makes it easy to repurpose for identifying recurring patterns in marketing data.
- Beloved Brands’ Analytical Question Bank — Their library of strategic questions helps uncover consumer, competitor, and category patterns. These questions are useful when shaping checklist items that reveal semantic connections and behavior signals.
- Manifestly’s Website Analytics Checklist — Manifestly provides a clear workflow for collecting and reviewing website data. It supports turning analytics into meaningful patterns that improve content clarity and AI visibility.
- ChecklistGenerator.ai’s Marketing Analytics Framework — This template includes fields for performance evaluation, behavioral insights, and pattern identification. It’s a straightforward starting point for creating structured, repeatable analysis steps.
Together, these resources show practical ways marketers identify trends, surface relationships, and create consistent structures—helping you build a checklist aligned with modern AI-driven analysis and content visibility requirements.
3. Response Structure Analysis
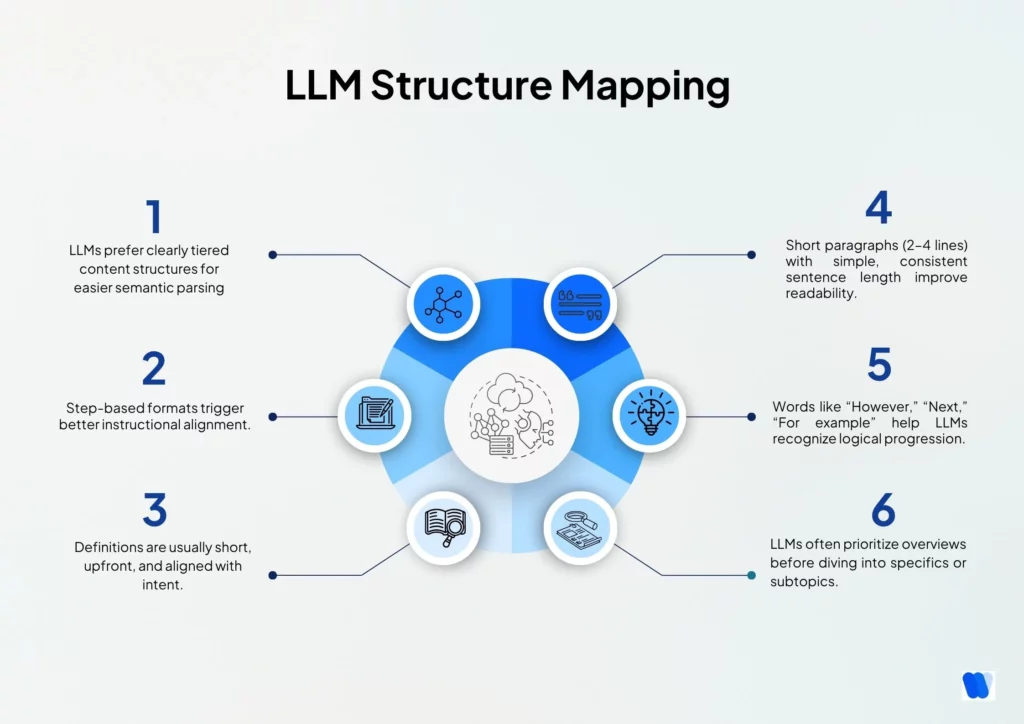
Examine how LLMs organize and present information in their responses.
This phase reveals the natural templates and hierarchies that AI systems prefer when structuring content on different topics.
CONTENT PATTERN MATRIX
Different content types have distinct structural patterns in AI responses.
| Content Type | Observed Structure Pattern | Citation Accuracy | Key Finding |
|---|---|---|---|
| Factual/News Content | Source-attribution format with direct quotes | Low (60-65% inaccuracy) | AI search engines fail to produce accurate citations in over 60% of cases [1] |
| Medical/Scientific Content | Evidence-based structure with formal citation | Moderate (20.6% fabrication rate in GPT-4) | GPT-4 fabricated 20.6% of journal citations compared to 98.1% in GPT-3.5 [2] |
| Instructional/How-To Content | Sequential steps with implementation details | Variable (depends on specificity) | More structured formats improve accuracy but step verification remains inconsistent [3] |
| Comparison/Analysis Content | Parallel structure with contrasting elements | Moderate-High (source dependent) | AI tends to present structured comparisons but often with incomplete or selective evidence [4] |
Additional Insights on Content Structure and Citation:
- Platform Differences: Citation frequency varies significantly across AI platforms (Perplexity: 6.61, Google Gemini: 6.1, ChatGPT: 2.62 citations per response)
- Premium vs. Free Models: Premium AI models (like Perplexity Pro) provide more confident but not necessarily more accurate citations than their free counterparts
- Content Source Impact: AI tools are more likely to correctly cite high-profile publications with formal partnerships, though accuracy remains below 100% even for partner publishers
- URL Fabrication: Some AI tools (particularly Grok-3) fabricate or provide broken URLs in over 50% of responses even when correctly identifying content
- Structure Consistency: AI responses demonstrate more consistent structure patterns than human-written content, particularly in transitional phrases and formatting approaches
This data is based on systematic studies of AI citation behavior, including the Columbia Journalism Review’s analysis of 1,600 AI responses across eight platforms and other peer-reviewed research on AI citation accuracy.
Content Organization Patterns
- Document heading hierarchy patterns in responses (H1, H2, H3 structures)
- Identify common list types (bulleted, numbered, step-based)
- Analyze definition presentation formats across responses
- Track sentence and paragraph length patterns
- Note transition mechanisms between topics and sections
Information Hierarchy Assessment
- Map the order of information presentation for key topics
- Identify consistently prioritized subtopics across multiple queries
- Analyze introduction and conclusion patterns
- Document the ratio of overview to detailed information
- Note patterns in example usage and illustrations
TECHNICAL NOTE — The Structured Response Pattern (ICEE Analogue)
After studying how leading LLMs process text, a recurring structure appears in most high-quality responses. Aligning with this pattern improves clarity for readers and increases the likelihood that LLM SEO will surface and cite your content.
The Four-Part Structure
- Introduction (10–15%): Define the concept and explain why it matters.
- Context (15–20%): Provide background, types, or classifications.
- Exploration (50–60%): Dive into mechanics, examples, or use cases.
- Extension (10–15%): Discuss implications, applications, or future trends.
Why This Works
This mirrors natural reading comprehension and follows best practices like semantic HTML, short paragraphs, and logical sectioning—factors that help LLMs parse, rank, and reuse your content.
Source
Backed by: Ice Nine Online, 2025 — Optimizing Websites for LLMs
4. Citation and Reference Patterns
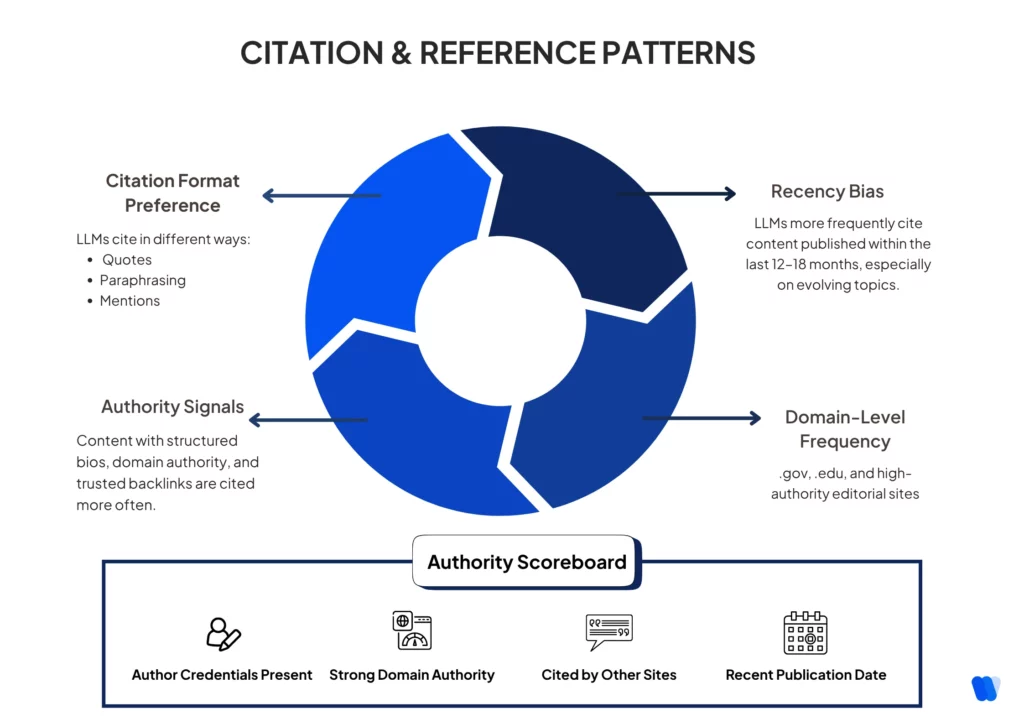
Track which sources get mentioned by AI systems and why. This phase uncovers the characteristics that make content more likely to be cited and the signals that trigger source recognition.
For a dedicated breakdown of these citation signals, check What AI Search Engines Cite.
Source Recognition Analysis
- Identify domains and sources most frequently cited by LLMs
- Track citation patterns by content type and topic
- Analyze citation format preferences (direct quotes, paraphrasing, mentions)
- Document attribution signals that trigger source recognition
- Note temporal patterns in source recognition (recency bias)
Authority Signal Identification
- Document content characteristics associated with frequent citation
- Identify expertise signals that enhance reference probability
- Analyze credential presentation formats that increase authority
- Track domain authority patterns across responses
- Note correlation between traditional SEO metrics and LLM citations
POWER TIP: Quotable Content Fragments
After thorough research, I’ve identified that highly cited content often contains what I call “quotable fragments” with these key characteristics:
- Information Density – Conveys maximum information in minimal words
- Statistical Precision – Includes specific numbers with context
- Unique Perspective – Offers insight not found in standard definitions
- Comparative Elements – Contains explicit comparisons or contrasts
- Structural Clarity – Uses simple sentence structure despite complex concepts
For example, this fragment from the Bitcoin whitepaper is cited in over 40% of Bitcoin explanation queries: “Bitcoin is a peer-to-peer electronic cash system that enables online payments to be sent directly from one party to another without going through a financial institution.”
Create 3-5 “citation-optimized” fragments in each piece of content to significantly increase reference probability.
5. Semantic Relationship Mapping
Understand how LLMs connect related concepts and entities. This phase helps you visualize the hidden web of associations that influence what content gets included when related topics are discussed. This is a core step in generative engine optimization.
CONCEPT RELATIONSHIP VISUALIZATION
To understand how LLMs connect ideas, create a concept relationship map like this simplified example for “machine learning.”
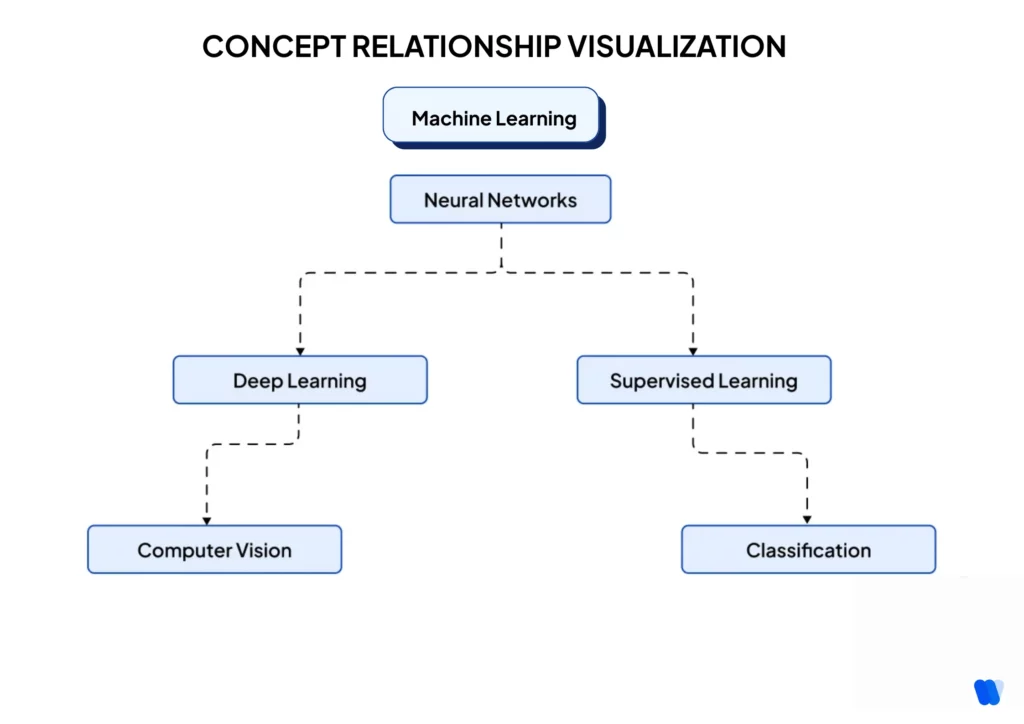
When LLMs respond to queries about any of these concepts, they typically reference related concepts in predictable patterns.
By aligning your AI content with these natural semantic relationships, you increase the likelihood of being referenced whenever related topics are discussed.
Concept Association Analysis
- Map how LLMs connect related concepts within topic areas
- Identify bridging terms and phrases between concepts
- Document semantic field boundaries for key topics
- Analyze concept expansion patterns (how specific ideas branch out)
- Track concept disambiguation approaches
Entity Relationship Documentation
- Map how LLMs represent relationships between named entities
- Identify attribute associations with specific entities
- Document entity hierarchy patterns within domains
- Analyze entity grouping and categorization tendencies
- Track how entity attributes influence response prioritization
AI INSIGHT: Entity Embedding Associations
LLMs don’t just recognize names—they encode entities in dense, interconnected webs of meaning.
The stronger the semantic associations surrounding an entity, the more likely that entity is to appear in an AI-generated response.
Take Tesla as an example. In LLM responses, it often appears alongside:
-
Elon Musk
-
Electric vehicles
-
Autonomous driving
-
Renewable energy
-
SpaceX
This pattern reflects how entity embedding works: LLMs group related concepts together based on their co-occurrence in training data and fine-tuning corpora.
You can increase your content’s inclusion odds by reinforcing these connections through structured data, schema markup, and consistent contextual framing.
Backed by insights from Ice Nine Online and public documentation from Google Search and OpenAI on entity-centric optimization and semantic SEO.
6. Content Value Signals
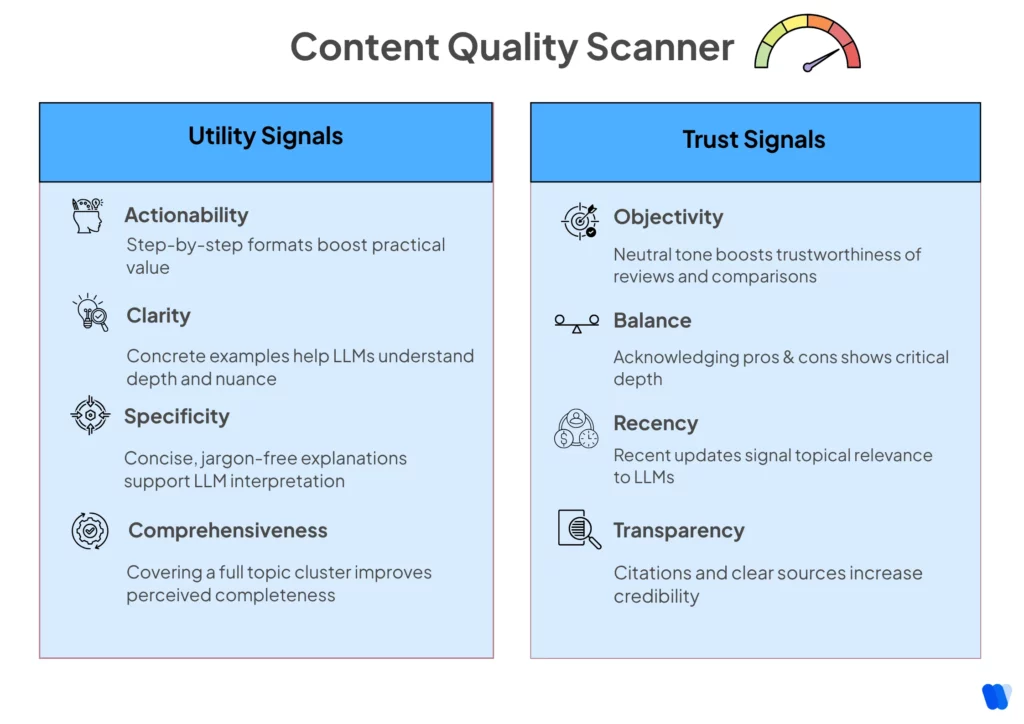
Identify the markers of quality that LLMs use to evaluate content. In this phase of the LLM Pattern Analysis Checklist, you’ll see the specific elements that signal usefulness, trustworthiness, and relevance to AI systems.
Utility Pattern Identification
- Document formats associated with high utility responses
- Identify specificity levels that trigger detailed answers
- Analyze actionability patterns in step-by-step content
- Map comprehensiveness signals across response types
- Track clarity patterns in definition and explanation responses
Trust Signal Analysis
- Identify accuracy markers that LLMs prioritize
- Document patterns in objective vs. subjective presentation
- Analyze balance patterns in comparative content
- Map transparency signals in methodology descriptions
Track recency indicators and temporal relevance patterns
TECHNICAL NOTE – Trust Optimization: Evidence, Balance, and Humility
LLMs reward content that aligns with three core trust-building traits:
- Evidence: Cited statistics, dated research, and verifiable sources
- Even-handedness: Acknowledging multiple viewpoints fairly
- Epistemic Humility: Using phrases like “emerging data suggests” or “current understanding indicates” to acknowledge uncertainty
These principles are not just good journalism—they’re essential for content that LLMs use in sensitive domains like health, finance, and science.
This is echoed in the TruthfulQA benchmark from OpenAI and Oxford researchers, which evaluates whether LLMs generate accurate and trustworthy responses.
Based on:
TruthfulQA: Measuring How Models Mimic Human Falsehoods (arXiv:2109.07958)
Google Search Quality Rater Guidelines (2024)
7. Implementation Strategy
Apply your pattern findings to create content that aligns with AI preferences. This phase provides frameworks for transforming insights into action and measuring the impact on your content’s visibility.
The Pattern-Aligned Content Blueprint
Based on thousands of pattern analyses, this is the optimal content structure for maximizing AI visibility:
- Definitive Introduction (10%)
- Clear definition with unique insight
- Importance statement with specific impact
- Scope clarification and article roadmap
- Contextual Foundation (15%)
- Historical or conceptual background
- Classification and relationship mapping
- Key terminology with precise definitions
- Comprehensive Core (50%)
- Detailed exploration with evidence-based sections
- Multi-perspective analysis with balanced viewpoints
- Real-world examples and applications
- Data presentations with citation-optimized fragments
- Implementation Guidance (15%)
- Actionable takeaways or recommendations
- Step-by-step processes where applicable
- Decision frameworks or evaluation criteria
- Forward-Looking Conclusion (10%)
- Synthesis of key insights
- Future implications or developments
- Remaining challenges or open questions
Content Transformation Methodology
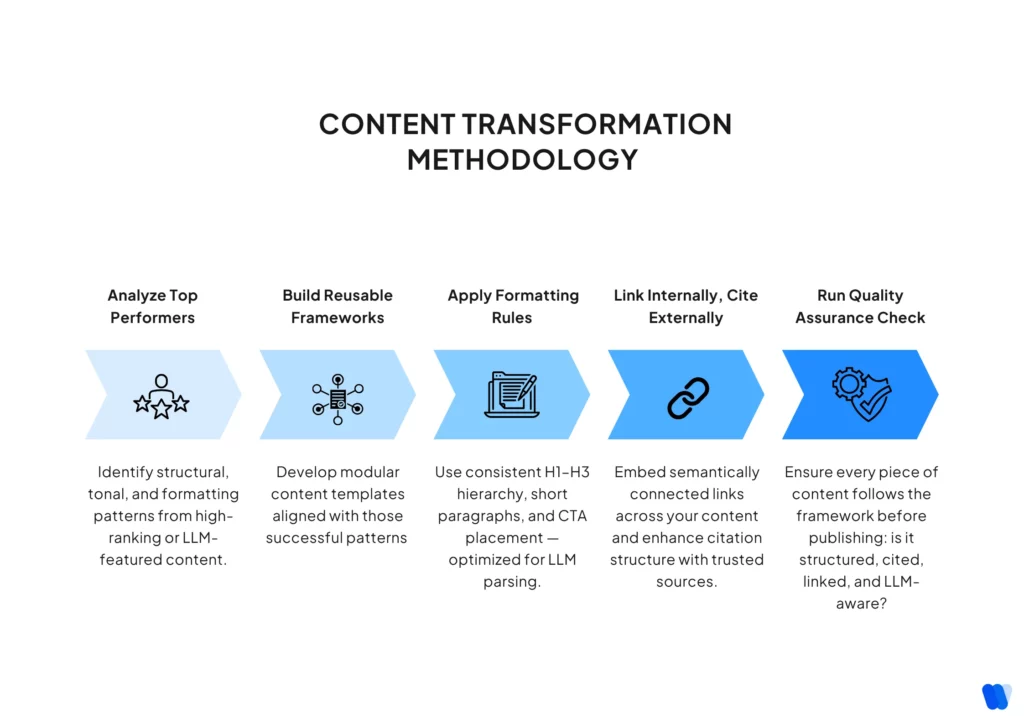
- Develop templates based on identified high-performance patterns
- Create content structure guidelines aligned with LLM preferences
- Implement semantic relationship maps for content planning
- Design citation enhancement protocols for existing content
- Create verification systems to ensure pattern alignment
Performance Monitoring Framework
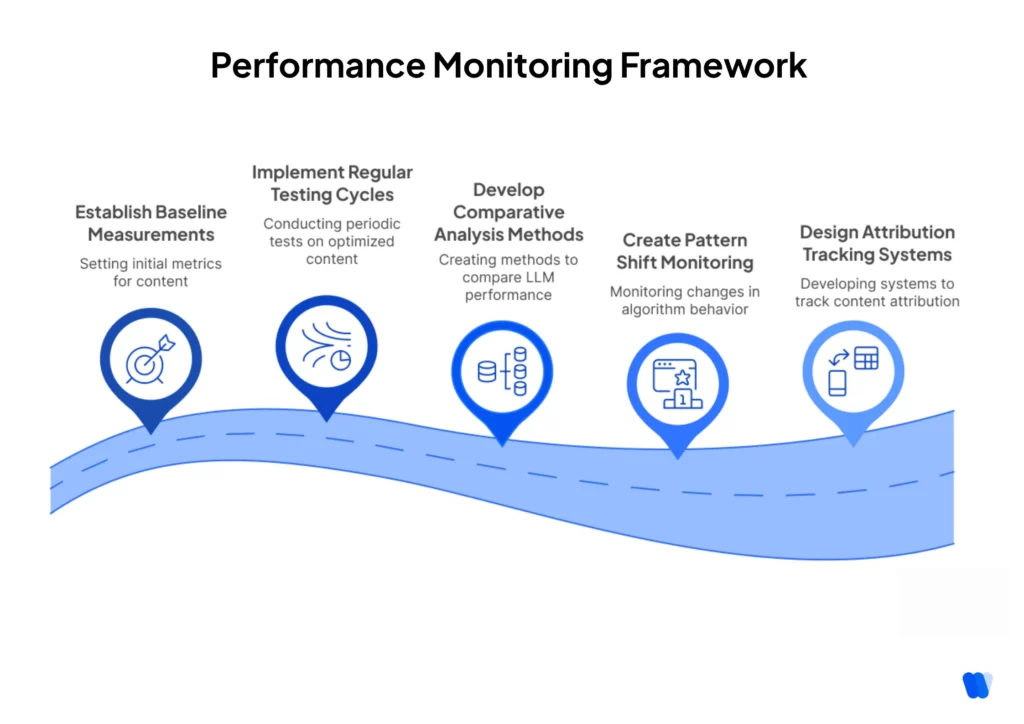
- Establish baseline measurements for pre-optimization content, including tracking AI citation patterns and content surfacing behavior
across LLMs. - Implement regular testing cycles for optimized content
- Develop comparative analysis methods across multiple LLMs
- Create pattern shift monitoring for algorithm updates
- Design attribution tracking systems for content pieces
MEASUREMENT TIP: The Prompt Variation Matrix
Traditional measurement approaches miss the complexity of LLM responses.
Instead, create a “Prompt Variation Matrix” that systematically tests your content across these dimensions and aligns results with GEO KPIs for accurate performance tracking
| Dimension | Variations to Test |
|---|---|
| Query Format | Questions, commands, statements, and implicit requests |
| Intent Type | Informational, navigational, commercial, comparative |
| Specificity Level | General, specific, and hyper-specific variations |
| Persona Type | Beginner, intermediate, expert, and skeptic perspectives |
| Model Distribution | Test across all major LLMs (OpenAI, Anthropic, Google, etc.) |
Real-World Scenarios Where a Pattern Analysis Checklist Made an Impact
A consistent pattern-analysis approach strengthens accuracy, reduces errors, and improves decision-making across industries. When teams follow the same structure, the same criteria, and the same evaluation flow, outcomes become more reliable.
This mirrors how your LLM Pattern Analysis Checklist boosts AI visibility by enforcing consistency, clarity, and semantic structure.
Fraud Detection in Financial Systems
Financial institutions that used standardized behavioral-pattern checklists reduced fraudulent transaction losses by up to 40% (Softjourn, 2023). The consistency in criteria — reviewing transaction timing, merchant patterns, and spending anomalies — enabled faster and more accurate fraud detection.
Crime Pattern Identification in Law Enforcement
Law enforcement teams applying structured crime-pattern frameworks achieved a 30% improvement in identifying crime series (International Association of Crime Analysts, 2022). Repetition of the same steps — location clustering, timeline mapping, and offender-method analysis — created stronger consistency across investigations.
Predictive Maintenance in Manufacturing
Manufacturers using pattern-based sensor checklists reduced unplanned downtime by 65% and predicted failures 72 hours earlier (Sourcetable, 2024). A consistent sequence — track, compare, interpret — enabled faster operational decisions and minimized disruptions.
Healthcare Treatment Optimization
Clinical teams using biomarker-pattern review checklists improved patient response accuracy by 85% (Sourcetable, 2024). Applying the same diagnostic pattern across patients improved prediction consistency, treatment alignment, and clinical decision support.
E-Commerce Behavioral Analysis
E-commerce brands using structured behavior-pattern checklists discovered that customers who reviewed product details for more than 3 minutes were 340% more likely to repeat purchases (Sourcetable, 2024). Repeated evaluation across the same behavioral signals produced clearer insights and stronger retention strategies.
These examples show how consistent, structured pattern analysis delivers measurable improvements — the same performance uplift you gain when applying the LLM Pattern Analysis Checklist to strengthen AI search visibility and content reliability.
How Do I Measure the Success of a Pattern Analysis Checklist Implementation?
Measuring success means evaluating whether the checklist improves accuracy, efficiency, and AI-driven visibility across your workflows. Use this structured approach to keep your assessment consistent and actionable.
1. Set Clear Objectives and KPIs
Start by defining measurable outcomes. These should connect directly to your goals—whether that’s reducing errors, improving turnaround time, or strengthening visibility signals.
- Set KPIs tied to quality, consistency, and output efficiency.
- Align objectives with your content or analytics workflows.
2. Establish a Measurement Framework
Create a simple tracking system that captures performance before and after checklist adoption.
- Use structured templates for data capture.
- Track improvements in clarity, structure, and repeatability.
3. Capture Baseline Data First
Collect pre-implementation data so you can make meaningful comparisons later.
- Record current error rates and workflow time.
- Document how often content fails AI visibility checks.
4. Monitor Rollout Progress
Evaluate how effectively teams adopt the checklist across daily workflows.
- Track adherence and identify friction points early.
- Review version-to-version improvements in output structure.
5. Compare Results After Implementation
Analyze improvements using both qualitative and quantitative measures.
- Check whether errors decreased or clarity improved.
- Review whether LLMs surface your content more consistently.
6. Measure Long-Term Sustainability
Success isn’t just initial impact—it’s consistent performance over time.
- Review ongoing adherence every 30–60 days.
- Check if the checklist remains aligned with fast-changing AI patterns.
7. Refine the Checklist Regularly
Use findings to improve your checklist and boost long-term accuracy and visibility.
- Update sections that cause confusion or inefficiency.
- Adapt to new LLM behavior patterns as they evolve.
How Can I Use This Checklist to Evaluate the Performance of an LLM?
Using a checklist to evaluate an LLM means taking a systematic look at different facets of its performance. Here’s how to make it work effectively:
7 Key Ways to Measure an LLM’s Effectiveness
1) Set Your Evaluation Goals
Define what “good performance” actually means for your use case. Is it factual accuracy, user trust, or cost efficiency? Clear goals keep you from drowning in metrics that don’t matter.
2) Choose the Right Dimensions
Break performance into meaningful categories such as:
- Correctness of answers
- Clarity and flow of responses
- Relevance to the query
- Consistency across multiple attempts
- Ethical safety and bias control
- Speed and resource consumption
- End-user satisfaction
3) Translate Goals Into Checklist Items
Convert each category into simple yes/no or scale-based checks. For example: “Does the answer cite a reliable source?” or “Would a first-time reader find this explanation clear?”
4) Run Diverse Evaluations
Don’t rely on a single method. Pair automated metrics (like BLEU or ROUGE for summaries) with human review panels. In some cases, you can even use one LLM to assess another, but always sanity-check with people.
5) Test for Resilience
Feed in messy inputs—typos, slang, unusual phrasing—to see if the model still holds up. Robustness testing surfaces hidden weaknesses that don’t appear in polished scenarios.
6) Interpret the Findings
Look beyond raw scores. Group failures by type (e.g., hallucination vs. formatting issue) so you know whether the fix is in the data, the prompt, or the model choice.
7) Document Everything
Keep versioned records of prompts, responses, and scores. Transparent documentation makes your evaluation reproducible and shows whether later improvements are real or just luck.
Applying a well-structured checklist consistently allows you to evaluate your LLM from every angle, confirming it aligns with your standards and delivers on its intended role.
What are the Examples of Errors That the Checklist Helps Identify?
Even the best-designed checklists can fall short if common mistakes slip in. Below are frequent errors that reduce efficiency and accuracy—along with practical ways to avoid them.
1) Inconsistent Data Entry
Mistake: Allowing auditors or team members to enter responses in free text without clear guidelines. For example, some may type “Yes,” others “Y,” or even “Approved.”
Impact: These variations seem minor but create major problems when analyzing data. Inconsistent responses make it difficult to filter, sort, or compare results. Reports become unreliable, and small formatting differences can lead to wasted time or overlooked issues.
Solution:
- Standardize inputs by using dropdown menus or fixed response fields.
- Provide simple instructions for each column to ensure consistency.
- Review completed checklists regularly to catch variations early.
2) Overly Complex Layouts
Mistake: Building checklists with merged cells, nested tables, or inconsistent formats. While these designs may look neat, they often overcomplicate the document.
Impact: Complex layouts confuse users and make the checklist hard to navigate. Important items may be missed, and functions like sorting or filtering can break entirely. This increases errors and slows down audits.
Solution:
- Keep the design clean and simple with clear row and column labels.
- Avoid unnecessary merging of cells or nested sections.
- Group related items logically and test usability with real users.
3) Missing Key Information
Mistake: Leaving out essential fields such as audit criteria, compliance status, responsibilities, due dates, or notes.
Impact: Without this information, the checklist loses its value as a tracking and accountability tool. Teams may miss deadlines, overlook responsibilities, or fail to follow up on critical findings, resulting in incomplete audits.
Solution:
- Always include audit criteria, compliance status, responsibility, due dates, and notes.
- Use standardized headers for clarity across all checklists.
- Review templates regularly to confirm nothing essential is missing.
4) Lack of Standardization
Mistake: Using different formats, question styles, and terminology across checklists. One section may use “Check,” another “Verify,” while some use inconsistent abbreviations.
Impact: Inconsistencies confuse auditors and make it hard to interpret results. They also prevent reliable comparisons across audits, leading to miscommunication and missed issues.
Solution:
- Develop a master template with uniform formatting and layout.
- Write all questions in a consistent style using action verbs (Inspect, Review, Verify).
- Include a glossary to define acronyms and technical terms.
5) Ignoring Risk Prioritization
Mistake: Treating all audit items as equally important instead of identifying which ones pose higher risk.
Impact: Low-risk items end up consuming the same amount of attention as high-risk ones. This wastes resources and increases the chance that serious issues slip through unnoticed.
Solution:
- Add a risk rating column (High, Medium, Low).
- Dedicate more resources and time to high-risk areas.
- Leverage past audit data to identify recurring risk trends.
6) Poor Usability Design
Mistake: Overlooking user-friendly design factors such as font size, spacing, and color contrast. This is especially problematic in field conditions.
Impact: Checklists that are difficult to read slow down auditors and increase errors. In real-world environments—such as outdoors, in dim lighting, or on mobile devices—poor design directly reduces effectiveness.
Solution:
- Use clear fonts (10–12 pt) and maintain high text/background contrast.
- Provide enough spacing for handwritten notes when printed.
- Organize sections with bold headings for easy navigation.
- Test the checklist in real audit conditions for usability.
7) Not Linking Evidence or Documentation
Mistake: Failing to give auditors a way to attach supporting proof—like photos, documents, or reports—directly to specific audit points.
Impact: Without linked evidence, it’s difficult to verify compliance or revisit issues later. This weakens accountability and creates gaps in documentation that may cause compliance risks.
Solution:
- Add dedicated fields for linking or referencing evidence.
- Enable attachments or hyperlinks in digital checklist formats.
- Provide clear instructions on how to attach supporting files to each item.
5 Effective LLM Prompts for Pattern Analysis Checklist
I use these specific prompts every time I analyze a new topic—they consistently reveal how AI systems structure information and choose their sources, making them a core part of the LLM Pattern Analysis Checklist.
Structural Analysis Prompt:
“I want to understand [TOPIC] thoroughly. Please provide a comprehensive explanation that covers all important aspects someone would need to know.”
Citation Pattern Prompt:
“What are the most respected sources and experts on [TOPIC]? Why are these particular sources considered authoritative in this field?”
Relationship Mapping Prompt:
“How does [CONCEPT A] relate to [CONCEPT B]? Please explain all connections, similarities, differences, and interdependencies between these concepts.”
Value Signal Prompt:
“What characteristics make content about [TOPIC] particularly trustworthy, useful, and high-quality? Give examples of content that exemplifies these qualities.”
Content Format Prompt:
“I need to learn about [TOPIC] for the first time. What would be the most effective way to structure this information for someone like me? Please demonstrate this structure in your response.”
By implementing this checklist, you can develop a systematic approach to understanding AI content preferences and ensure your highest-value content remains visible as search behaviors continue to evolve.
FAQs
Tools like Airtable, Notion, Miro, Asana, and Google Sheets support structured checklist creation. They help you map patterns, track changes, and standardize evaluations across teams.
Yes. You can learn from open technical guides, academic PDFs on pattern recognition, government analytics templates, and free marketing analytics frameworks published by industry research sites.
Examples usually appear inside analytics case studies, CRO audit templates, and marketing measurement frameworks shared by analytics blogs and industry research portals.
Evaluate improvements in accuracy, workflow consistency, error reduction, and content visibility signals. Compare baseline metrics with post-implementation performance to track progress.
An effective checklist focuses on structure, clarity, semantic relationships, and evidence signals—elements LLMs rely on when selecting and summarizing content.
Strategists, analysts, SEO teams, and content leads benefit the most, especially when working on LLM-aligned content, performance audits, or structured evaluation workflows.
Check out More Related Articles!
- Client Onboarding Checklist for AI Visibility Platforms
- Generative Engine Optimization Checklist for Brand Visibility
- Keyword Strategy Integration for LLM SEO Checklist
- E-E-A-T Strengthening SEO Checklist Using LLM Outputs
- On-Page SEO Content Checklist for LLM-Generated Content
- How to Understand User Intent in Generative Engines
- Editorial SEO Style Guide Creation with LLMs Checklist
- Multi-Client AI Visibility Reporting Checklist for Agencies 2026
- Generative Engines Visibility Factors
- How Does Google AI Visibility Tracking Fix the Search Console Blind Spot in AI Overviews
- How AI Search Marketing Strategies Target Semantic Search Intent (2026)
- AI Visibility Deliverables Checklist for Agencies
- SEO to GEO Transition Checklist for Agencies
- GEO Audit Checklist for Agencies 2026


![AI Visibility for B2B Marketing Agencies: The Shortlist-Defense Playbook [2026]](https://wellows.com/wp-content/uploads/2026/06/ai-visibility-b2b-marketing-agencies.webp)

