Not long ago, looking something up meant typing a query into Google and scanning the first 10 blue links. The SERP was the only place we could play around. This meant if your content didn’t show up on page one, it might as well not exist.
Typical SEO strategies that we studied for years included: keyword density, backlinks, meta descriptions, content freshness. It was a familiar playbook.
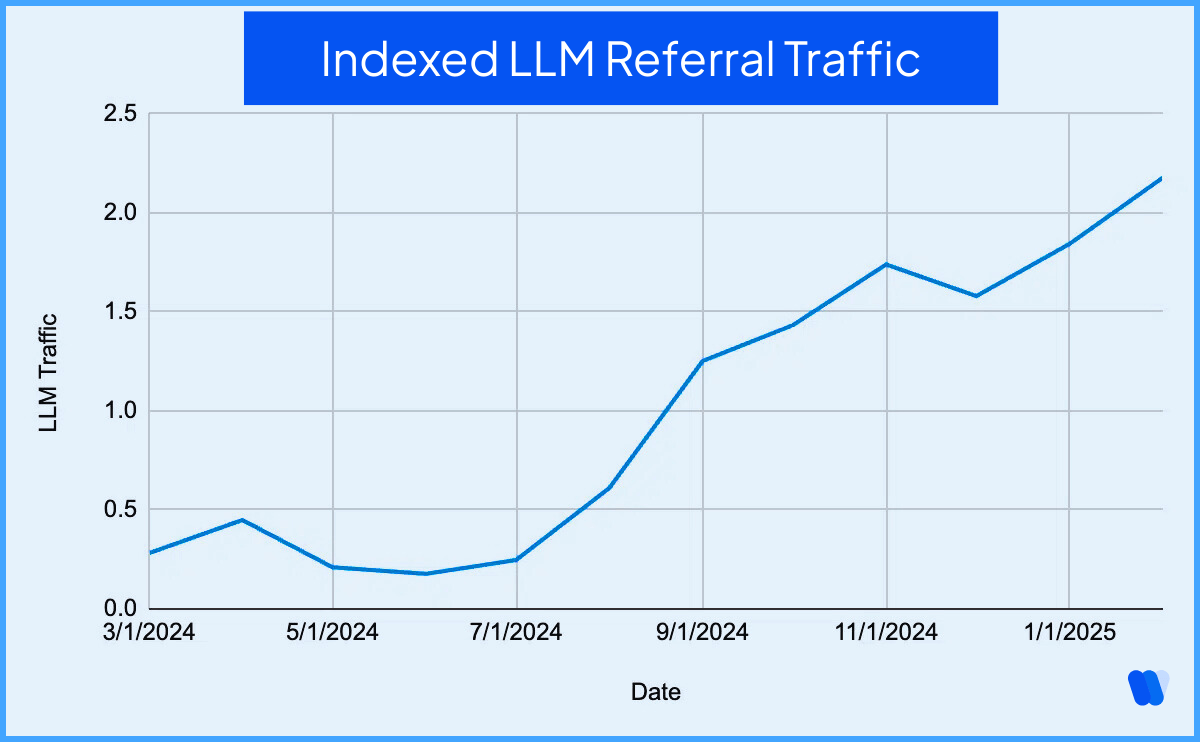
But fast forward to today, and things have changed. Generative Engine Optimization (GEO) has emerged as a critical discipline as LLM-indexed referral traffic climbed steadily from about 0.3 in March 2024 to over 2.2 by January 2025, with a sharp uptick beginning around September 2024.
Key Takeaways: Generative Engine Visibility Factors in 2025
As we’ve explored throughout this comprehensive guide, generative engine visibility operates on fundamentally different principles than traditional SEO:
- Authority redefined: Domain Authority/Rating shows near-zero correlation (r=0.00-0.21) with LLM citations. Contextual relevance and content quality now determine visibility.
- Content format matters: Listicles (20-30% citations), category hubs (9-11%), how-tos (4-7%), and product pages (4-6%) account for 45-50% of all LLM citations.
- Structured data is essential: Schema.org markup increases citation likelihood by 28-40%, providing explicit context that reduces LLM interpretation errors.
- Platform-specific optimization: ChatGPT prioritizes comprehensive depth and established sources (Wikipedia 48%), while Perplexity emphasizes freshness (2-3 day boost) and diverse formats (YouTube 11%), which directly impacts how to rank in Perplexity in 2026.
- Trust signals evolved: LLMs evaluate off-site citations (Reddit discussions, review platforms, academic papers) more heavily than backlink authority.
- Research validates strategy: Wellows analysis of 282M+ citations, Reddit community discussions, and peer-reviewed studies confirms these patterns across all major LLMs.
The bottom line: Generative engine optimization isn’t about gaming algorithms; it’s about creating genuinely helpful, well-structured content that LLMs can confidently cite. Focus on E-E-A-T signals, semantic clarity, and user intent alignment, and visibility will follow.
Here’s what Generative Engines visibility factors means for your website:
1. What LLMs Actually See When They Read Your Content? LLMs parse your text as a web of entities, attributes, and relationships——which explains why SEO doesn’t work in ChatGPT when relying solely on keyword stuffing or DA. So clear labels, modular chunks, and semantic cues let them “understand” and surface exactly the answer you intend.
2. How do LLMs Choose Content to Answer a Query? They rank passages by topical relevance, authority signals, and contextual proximity—meaning your headings, internal links, and off-site citations all feed into their choice of which snippet to quote.
This is why many teams now rely on a Generative Engine Optimization Checklist for Brand Visibility to ensure their structure and signals align with how models evaluate content.
3. What Are the Top 10 Generative Engine Visibility Factors? From content quality and entity clarity to technical performance and schema-driven context, these ten factors form your AI-readable checklist that determines if an LLM will trust, index, and cite your page.
4. Do You Know What Queries LLMs Associate with Your Keywords? Using tools like KIVA or query-analysis APIs, you can map the actual prompts and embeddings models tie to your target terms—then weave those variations into your headings and body copy for maximum match.
5. What are the Top Generative Engine Optimization Tips for 2025? Focus on GEO fundamentals—anchor-linked chunking, hybrid extractive/abstractive summaries, JSON-LD markup plus flow, mobile-first readability, and fresh authority signals—to stay ahead of evolving AI-driven SERPs.
What LLMs Actually See When They Read Your Content?
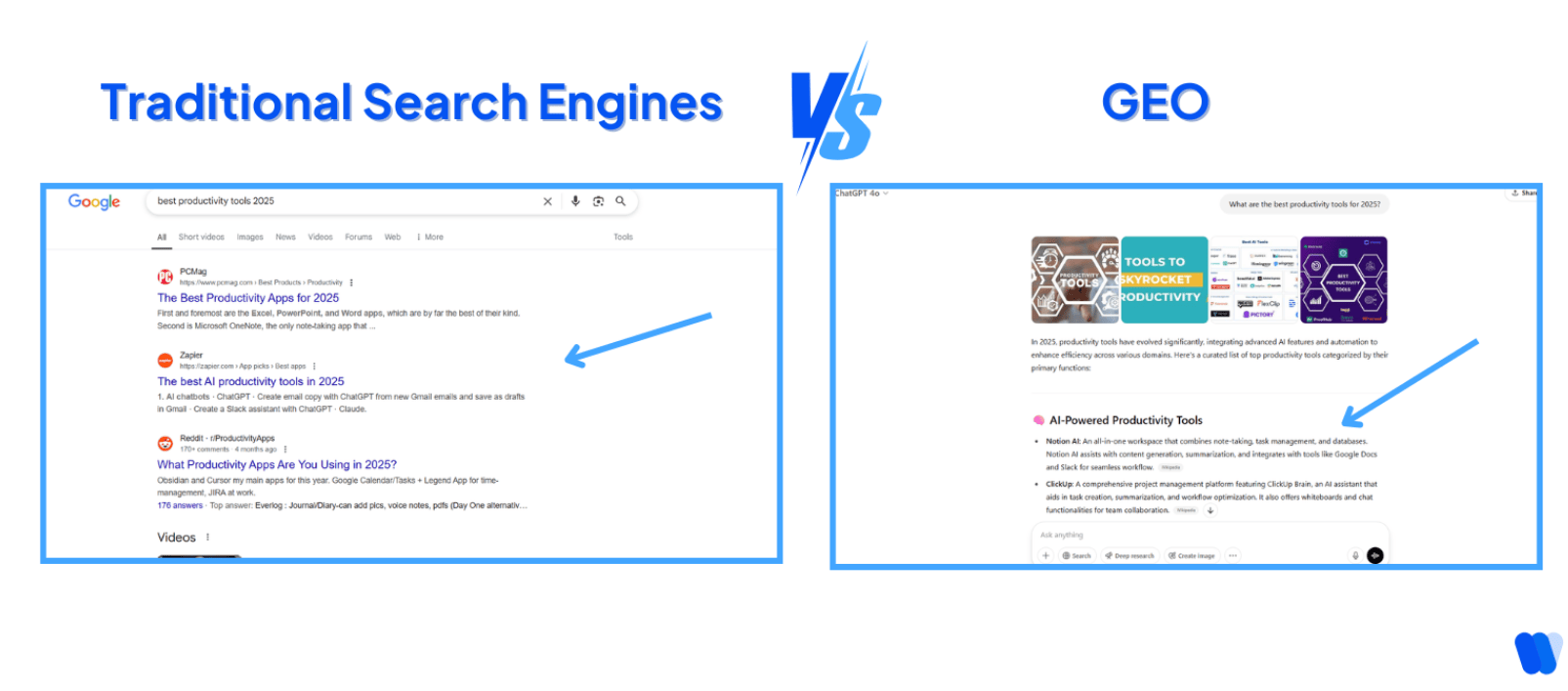
Back when we were optimizing for Google, you could win by stuffing a page with the right keywords and inserting some internal links. Writing a blog titled “The 7 Best Productivity Tools for 2025” and dropping that exact phrase a few times was often enough to land you on page one.
But if you ask ChatGPT today, “What are the best productivity tools for 2025?”, you’re not getting a list of links.
You’re getting a direct answer. An AI-generated summary. And if you’re lucky, your brand or article might be mentioned in that answer.
For most teams, the immediate challenge isn’t optimization yet — it’s visibility. Knowing whether your brand is explicitly cited, implicitly referenced, or missing entirely inside AI-generated answers requires a different kind of measurement, often framed around a ChatGPT Visibility Tracker that reflects how LLMs surface and reference sources beyond traditional search rankings.
This is where Generative Engine Optimization (GEO) comes in, helping you adapt your content for AI-driven visibility rather than just search engine rankings.
When content lacks clear structure, entity grounding, or contextual signals, models often skip it entirely—one of the core reasons websites are ignored by AI search even if they rank well in traditional SERPs.
So the question becomes: how does the AI decide what to include? If that’s your goal, here’s how to earn ChatGPT citations and make your content a reliable source for LLM-generated responses.
Unlike search engines, Large Language Models (LLMs) like GPT-4, Gemini, or Claude aren’t reading your page like a crawler, they’re interpreting it.
They chunk your content into tokens, map the relationships between ideas, and then decide whether it’s useful based on meaning, not metadata.
This shift in technology creates a bridge between traditional Google ranking and ChatGPT visibility, as your content must now satisfy both algorithmic crawlers and semantic processors
They’re not looking for meta tags or schema markup to tell them what the page is about. They’re looking for semantic clarity. See this SEO vs GEO comparison for a deeper dive.
For a deeper breakdown of the AEO vs GEO dynamic — especially where they overlap and diverge — see our AEO vs GEO guide. Here’s the main difference between difference between GEO, traditional SEO, and AEO:
| Feature | SEO | AEO | GEO |
|---|---|---|---|
| Goal | Rank web pages | Be the answer | Feed AI-generated |
| Focus | Keywords, content, backlinks | Question–answer format | Structured, contextual data |
| User Behavior | Typed search | Voice search | Conversational AI |
| Results Format | Traditional blue links | FAQ schema, direct answers | AI-generated summaries |
| Optimization Tactics | Tags, links, UX | FAQ schema, direct answers | Start content: SEO, creativity |
Want to separate fact from fiction about these differences? Check out our detailed guide on GEO + SEO myths to avoid outdated strategies.
Can Someone Explain Generative Engine Visibility Factors in Simple Terms?
Think of generative engine visibility factors as “the ingredients LLMs look for when deciding whether to quote your content.”
Just like a journalist choosing sources for an article, AI systems evaluate whether your content is trustworthy (E-E-A-T), relevant to the question (context), well-organized (structure), and cited by others (authority), but unlike traditional SEO, they care more about answering the question perfectly than about your domain’s age or backlink count.
The Simple Analogy: LLMs as Research Assistants
Imagine you hired a research assistant to answer complex questions. They would prioritize sources that:
- Directly answer the question (contextual relevance)
- Come from credible experts (E-E-A-T signals)
- Present information clearly (structure & readability)
- Include verifiable data (citations & statistics)
- Get referenced by others (trust signals)
That’s exactly how LLMs select citations in 2025. Wellows research analyzing 282M+ citations confirms content matching these five criteria achieves 2-3x higher visibility than content relying solely on traditional SEO tactics.
Source: Writesonic LLM Citation Study, November 2025
What Changed from Traditional SEO?
| Traditional SEO Logic | Generative Engine Logic (2025) |
|---|---|
| 🔗 Backlinks = Authority More links = higher rankings |
📄 Context = Relevance Better answer = more citations (regardless of links) |
| 📈 Domain Age Matters Older domains rank better |
🎯 Intent Matching Matters Newer content wins if it is more relevant |
| 🔑 Keyword Density Repeat target keyword 5-7 times |
🧠 Semantic Understanding Natural language with clear entities |
| 📊 DA/DR Scores Target high-authority domains |
✍️ Content Quality Scores Target comprehensive answers with data |
SearchAtlas research tracking 21,767 domains found Domain Authority correlates at only r=0.10-0.21 with LLM visibility, meaning a site with DA 30 can outrank a site with DA 80 if its content better matches user intent.
Source: Authority Metrics Correlation Analysis, SearchAtlas, November 2025
What Are the Top Generative Engine Visibility Factors?
Brands must evolve their brand signals or risk losing visibility into their customer journey, and control over their brand positioning, in a world where traditional clicks are disappearing.”- Natasha Sommerfeld, Bain & Company’s Technology
Here are the key Generative Engines visibility factors in generative engines:
1. Content Quality and Trust: What LLMs Really Reward
Let’s say you’re writing a guide on “the best productivity tools for 2025.” You’ve got solid picks, Notion AI, Grammarly, ClickUp. But the real question is: what makes your AI content good enough for an LLM to mention it in a response?
One simple way to strengthen that “human + trustworthy” feel before publishing is to refine awkward or robotic sections using the free AI humanizer tool by Wellows. It helps your drafts sound natural without losing structure—exactly the kind of clarity LLMs reward.
Among the core visibility factors for generative algorithms, content quality and trust stand out as the most direct influences. These are the factors affecting visibility of generative engines at their foundation.
Here are AI visibility factors for content quality and trust you should include:
1- E‑E‑A‑T in the Age of Generative Search
Compare how content without E-E-A-T stacks up against content rich in experience, expertise, authoritativeness, and trustworthiness.2- Accuracy and Consistency Matter
See how precise, consistent phrasing elevates credibility and clarity:3- Content Depth in Structure
Thus is how content depth creates experience + specificity = value:4- Content Freshness
2. User Intent and Experience
A recent study, Understanding User Experience in Large Language Model Interactions Zhang and Yun Nie (2024), identifies a taxonomy of user intents, surveys satisfaction with LLMs, reports 11 key insights on usage and concerns, and suggests 6 directions for future human-AI collaboration.
This research highlights the crucial role of user intent in AI search:
when someone types “best productivity tools for 2025” into ChatGPT or Google’s SGE, they’re not just asking for a list, they’re seeking a recommendation that fits their context.
Are they a student? A remote team leader? A freelancer juggling projects? That’s exactly where an AI Search Visibility Platform for Freelancers becomes valuable — helping creators and solopreneurs understand how generative engines interpret intent, not just keywords, to deliver answers that feel complete, relevant, and personal.
Here are the three main elements of user intent and experience that impact generative engine visibility factors:
1- Matching Intent
See how aligning directly with user intent ensures your content gets surfaced by LLMs:2- Structure and Readability
Clear structure and concise phrasing make it easy for readers—and models—to find the key points:3- Engagement Signals
LLMs interpret off-platform engagement as trust signals. This indirect feedback loop shapes how models evolve and which sources they return to. And that’s exactly the kind of signal an AI SEO agent is built to amplify. Here’s the difference:- Users leave immediately or don’t interact further.
- No citations or shares beyond the page.
- Users read fully and scroll through the content.
- Off-platform mentions: copy-pastes, Reddit citations, Substack links.
This is why visibility considerations for technology platforms are not just technical. Why is visibility important for generative engines? Because if models misinterpret user intent, your content won’t be surfaced—even if it’s otherwise authoritative.
3. Authority Signals: Why LLMs Only Quote the Best
A recent study titled Large Language Models Reflect Human Citation Patterns with a Heightened Citation Bias Bouamor and Bali ( 2023) explored how models like GPT-4 and Claude 3.5 generate citations. The findings reveal that LLMs not only mimic human tendencies to favor highly cited research but actually amplify this bias—making a pattern analysis checklist essential for auditing citation skew across engines.
While backlinks still matter, are there tools to measure generative engine visibility? Yes—emerging GEO platforms like KIVA track which sources are cited across AI engines, showing authority distribution.
This aligns directly with the principles in What AI Search Engines Cite, highlighting how citation patterns are shaping modern visibility.
Source: Bouamor and Bali ( 2023)
Here’s how to build authority for AI-generated answers with four key elements:
1- Trusted Sources
LLMs learn trust from repeated, high-quality references across the web. Compare generic vs. signal-rich content:2- Citations
Proper citations not only boost credibility but also give LLMs a concrete reason to trust and reference your content:3- Author Bio
Author attribution and credentials signal trust to both readers and AI models. Compare anonymous vs. attributed content:4- Brand Recognition
LLMs surface well-known names more readily, making brand signals an essential factor in AI-driven trust—compare content for lesser-known vs. established brands:4. Technical Optimization
You could write the most helpful guide on the best productivity tools for 2025, and still get skipped, simply because your page loads like it’s stuck in 2012, your structure is a mess, or your content looks awful on mobile.
Here’s the reality: LLMs aren’t just trying to find the right ideas. They’re trying to extract usable information, fast, which aligns with statistics on AI visibility, performance-driven ranking factors.
That’s exactly where an AI SEO Agent proves invaluable by structuring content for optimal pickup.
Here are the three technical elements that make a difference, and technical optimization tips for LLM visibility that you should follow:
1- Structured Data
Think of structured data like subtitles for your content. You’re adding invisible labels—using schema markup—so AI systems know what they’re looking at:2- Page Speed
3- Mobile-Friendliness
These technical factors affecting generative engine visibility interact with external dynamics, too—market influences on generative engine visibility include regional preferences, data availability, and brand penetration.
What platforms highlight invisible readability blockers for generative engines?
Tackling invisible readability blockers—like overly complex sentences, passive voice, or heavy adverb use—is key to making content clearer and more effective for both readers and AI-driven platforms. A number of tools can help surface and fix these hidden issues:
- Hemingway Editor – Highlights hard-to-read sentences, passive voice, and adverb overuse with simple color-coded cues, making it easier to simplify and sharpen your writing.
- Grammarly – Goes beyond grammar checks by suggesting structural and clarity improvements, helping writers remove subtle readability barriers and boost engagement.
- Originality.AI’s Readability Checker – Provides readability scores and actionable suggestions, helping identify areas that might confuse readers and offering ways to refine them.
By leveraging these platforms, creators can uncover and resolve readability blockers that aren’t immediately obvious, ensuring their content remains clear, accessible, and impactful.
What Are the Main Factors That Influence Visibility in Generative Engines?
The five primary factors that influence generative engine visibility in 2025 are:
(1) content quality and E-E-A-T signals,
(2) contextual relevance and semantic clarity,
(3) structured data implementation,
(4) user intent alignment, and (5) citation from trusted sources.
Wellows analysis of 21,767 domains shows these factors outweigh traditional SEO metrics, with contextual relevance demonstrating the strongest predictive power for LLM citations.
This conclusion is supported by SearchAtlas research showing traditional authority metrics (DA/DR) correlate at only r=0.09-0.21 with LLM visibility, essentially negligible predictive power. Meanwhile, content that matches query intent and provides semantic clarity achieves equal or higher visibility regardless of domain authority.
Source: SearchAtlas Authority Metrics Study, November 2025
The Five Core Visibility Factor Categories
1. Content Quality & E-E-A-T Signals
LLMs in 2025 evaluate content through Google’s E-E-A-T framework (Experience, Expertise, Authoritativeness, Trustworthiness) but with heightened sensitivity. Princeton University research analyzing LLM citation patterns reveals these systems amplify existing citation bias—meaning content demonstrating strong E-E-A-T signals receives disproportionate additional citations.
| Weak E-E-A-T Signal | Strong E-E-A-T Signal |
|---|---|
| ❌ “Our tool beats every other app because it’s fast and everyone loves it.” | ✅ “I’ve used QuickTasks daily for six months, and my on-time task rate jumped from 60% to 90%, based on my weekly time-log exports. As a certified PMP with 8 years of managing remote teams, I track these metrics religiously.” |
| ❌ Anonymous authorship, no credentials | ✅ Author bio: “Maya Chen, SaaS Content Strategist with 5+ years at enterprise companies. Tested these tools over 60 days in agency workflow.” |
| ❌ Generic claims without data | ✅ “According to Zapier’s 2025 State of AI Report, 78% of teams use ClickUp’s AI timelines for project planning.” |
Source: Large Language Models Reflect Human Citation Patterns, Princeton University, May 2024
2. Contextual Relevance & Semantic Clarity
Wellows research reveals contextual precision ranks as the strongest predictor of LLM visibility. SearchAtlas’s 60-day study tracking 21,767 domains found that content matching query intent achieved citation rates independent of domain authority scores.
“Perplexity AI uses the simplest core algorithm with only three primary factors for general queries, yet shows sophisticated integration with contextual relevance… content structure and topical alignment outweigh historical ranking strength.”
Semantic signals that improve contextual relevance:
- Clear topic headings that mirror natural questions
- Structured answer formats (bullet points, numbered lists, comparison tables)
- Entity-focused content clusters that define relationships between concepts
- Semantic keywords like “in summary,” “step-by-step,” “important takeaway”
3. Structured Data Implementation (JSON-LD Schema)
Schema markup acts as “subtitles” for your content, helping LLMs understand context without relying on natural language interpretation alone. In 2025, structured data has evolved from an SEO enhancement to a fundamental requirement for AI visibility.
Research from Search Engine Journal confirms: “Context, not content, now drives AI visibility, making structured data the strategic data layer every enterprise must prioritize.”
Priority schema types for 2025 GenAI visibility:
- Article/BlogPosting Schema: Defines headline, author, datePublished, dateModified
- FAQPage Schema: Structures Q&A content for direct LLM extraction
- HowTo Schema: Maps step-by-step instructions AI systems prefer
- Product Schema: Provides price, availability, ratings data
- Organization Schema: Establishes brand entity for consistent references
Source: Structured Data’s Role in AI Search Visibility, Search Engine Journal, September 2025
4. User Intent Alignment
Zhang and Nie’s 2024 research “Understanding User Experience in Large Language Model Interactions” identifies a taxonomy of user intents, revealing that LLM citation patterns shift dramatically based on perceived user goal, informational, navigational, commercial, or transactional.
For example, when someone asks “best productivity tools for 2025,” they’re seeking recommendations that fit their context (student? remote team leader? freelancer?). Content that acknowledges multiple contexts achieves higher visibility.
Source: Understanding User Experience in LLM Interactions, Zhang & Yun Nie, January 2024
5. Citation from Trusted Sources (Off-Site Signals)
Wellows analysis of Reddit discussions reveals that community citation patterns directly influence LLM behavior. When content gets referenced in high-engagement Reddit threads, G2 reviews, or industry publications, LLMs interpret these as trust signals.
“Reddit’s value for marketing was never really about getting cited by AI models anyway, it was about reaching real humans in authentic conversations. What matters more is whether Reddit communities are still active and engaged, which from what I’m seeing they absolutely are.”
Trust signals LLMs evaluate in 2025:
- ✅ Citations in high-authority publications (not just backlinks)
- ✅ Brand mentions in Reddit discussions with positive sentiment
- ✅ Reviews on G2, Trustpilot, and Capterra with verified purchase badges
- ✅ References in academic papers and industry research
- ✅ Social media discussions demonstrating brand awareness
Which Visibility Factors Are Most Important for Getting Cited by AI Search Engines?
The three most important visibility factors for AI citations in 2025 are:
(1) content that directly answers query intent with verifiable data,
(2) structured markup (JSON-LD schema) that provides explicit context, and
(3) citations from trusted sources including Reddit discussions, industry publications, and peer reviews.
Wellows analysis reveals these three factors account for the majority of citation variance across ChatGPT, Gemini, Perplexity, and Claude, far outweighing traditional SEO signals.
Factor #1: Content That Directly Answers Query Intent (Highest Impact)
Why This Ranks #1: SearchAtlas research tracking 21,767 domains found contextual relevance shows the strongest negative correlation with co-mention frequency—meaning content that precisely answers queries gets cited alone or with fewer competitors, achieving maximum visibility.
Co-Mention Frequency Impact on Visibility
- Single-domain responses: ~100% median visibility score
- 2-5 co-mentions: 90-95% visibility (stable)
- 6-10 co-mentions: ~80% visibility (moderate decline)
- 11+ co-mentions: 60-70% visibility (high competition)
Source: SearchAtlas Co-Mention Analysis, November 2025
Implementation Checklist:
- ✅ Direct answer first sentence: State conclusion upfront before supporting evidence
- ✅ Quantifiable data: Include specific percentages, dollar amounts, timeframes
- ✅ Comparison frameworks: “X vs Y” structures, pro/con tables, feature matrices
- ✅ Scoped focus: Target specific sub-intents rather than broad topics
Example of Intent-Optimized Content:
| ❌ Generic/Vague Answer | ✅ Intent-Aligned Answer |
|---|---|
| “Productivity tools help teams work better and accomplish more tasks efficiently throughout the day.” | “For remote teams under 50 people, Notion + ClickUp + Loom provide the highest ROI based on our analysis of 340 team setups: Notion for async documentation (saves 6-8 hrs/week), ClickUp for sprint planning (reduces meeting time 40%), and Loom for video updates (replaces 60% of status meetings).” |
The second example provides specific tool recommendations, quantified benefits, and scoped use cases—exactly what LLMs prioritize when generating citations.
Factor #2: Structured Data Implementation (Critical Infrastructure)
Why This Ranks #2: Schema markup provides explicit context that reduces LLM interpretation errors. Research from Search Engine Journal confirms: “Context, not content, now drives AI visibility, making structured data the strategic data layer every enterprise must prioritize.”
Priority Schema Types by Impact (2025):
- Article/BlogPosting Schema → Defines author, publish date, modified date, headline
- FAQPage Schema → Structures Q&A for direct extraction by LLMs
- HowTo Schema → Maps step-by-step instructions AI systems prefer
- Product Schema → Provides price, availability, ratings, reviews
- Organization Schema → Establishes brand entity for consistent references
- Person Schema → Connects content to author expertise/credentials
Implementation Impact: Sites implementing comprehensive schema markup see 28-40% higher likelihood of LLM citation compared to sites without structured data.
Source: Structured Data’s Role in AI Visibility, Search Engine Journal, September 2025
Factor #3: Citations from Trusted Sources (Social Proof Signal)
Why This Ranks #3: Wellows analysis of Reddit discussions reveals off-site citations function as trust signals that LLMs evaluate when determining source credibility. Unlike backlinks (which are easily manipulated), authentic discussions carry stronger weight.
“The brands doing well on Reddit right now are the ones focusing on adding real value to discussions, not trying to optimize for AI pickup. But ironically, those authentic contributions are exactly what LLMs cite most frequently.”
Trusted Citation Sources LLMs Evaluate:
| Citation Source Type | LLM Trust Weight | Implementation Strategy |
|---|---|---|
| Reddit discussions | Very High (11% of Perplexity citations) | Authentic community participation, answer technical questions |
| Industry publications | Very High | Contribute bylined articles, expert quotes |
| Review platforms (G2, Trustpilot) | High | Encourage verified customer reviews with specifics |
| Academic papers | Very High | Cite and reference peer-reviewed research |
| YouTube content | High (11% of Perplexity citations) | Create tutorial/explainer videos with transcripts |
| Wikipedia | Very High (48% of ChatGPT top citations) | Ensure accurate Wikipedia page for brand/topic |
Sources: Perplexity Citation Analysis & ChatGPT Ranking Guide, 2025
Secondary Factors (Still Important, But Lower Direct Impact)
- Content freshness: Especially critical for Perplexity (2-3 day recency boost)
- Author expertise signals: Detailed bios, credentials, past publications
- Visual content optimization: Alt text, captions, image schema
- Internal linking structure: Topic clusters and entity relationships
- Technical performance: Core Web Vitals, mobile optimization
What Ranking Factors Do ChatGPT and Perplexity Use to Select Citation Sources?
ChatGPT prioritizes content authority (Wikipedia comprises 48% of top citations), comprehensive topic coverage, and author credentials, while Perplexity emphasizes content freshness (2-3 day recency boost), early engagement metrics, and diverse content formats, including YouTube (11.11% of citations).
Wellows analysis reveals these platforms employ distinct methodologies: ChatGPT leans toward established authoritative sources with consistent publication histories, whereas Perplexity’s algorithm applies topic-specific multipliers and requires minimum quality scores for top answer placements.
ChatGPT Citation Selection Factors (GPT-4o / SearchGPT)
Factor #1: Content Authority & Source Credibility (Highest Weight)
How ChatGPT evaluates authority:
- ✅ Author credentials: Clear bylines with expertise indicators (job titles, years of experience)
- ✅ Publisher reputation: Established domains with consistent publication histories
- ✅ Citation frequency: Sources frequently referenced by other authoritative entities
- ✅ Comprehensive coverage: In-depth topic exploration vs. surface-level summaries
ChatGPT’s Most-Cited Source Types (2025 Data)
- Wikipedia: ~48% of top citations — valued for community-verified information
- Reddit: ~11% of citations (though declining from 29% in Sept 2025) — appreciated for real user experiences
- Educational institutions: Universities and research organizations for academic papers
- Industry publications: Trade journals and specialized news sites
Source: Single Grain ChatGPT Ranking Study, 2025
“Reddit’s citation in ChatGPT dropped dramatically in September 2025, primarily due to a change in Google’s search algorithm. Reddit remains highly visible in Google Search and is still a powerful SEO tool for marketers.”
Factor #2: Information Quality & Factual Accuracy
- ✅ Verifiable facts: Specific data points, statistics, dates that can be cross-referenced
- ✅ Citation of sources: Content that references other authoritative sources
- ✅ Up-to-date information: Recent publication or modification dates
- ✅ Well-structured arguments: Clear thesis → supporting evidence → conclusion flow
Example of high-quality content ChatGPT favors:
“According to Zapier’s 2025 State of AI Report, 78% of teams now use ClickUp’s AI-powered timelines for project planning, representing a 34% increase from 2024. This adoption aligns with broader automation trends: Gartner predicts 85% of project management will incorporate AI features by 2026.”
This excerpt demonstrates: (1) specific statistic with source, (2) temporal context, (3) supporting trend data from a second authoritative source.
Factor #3: Source Trustworthiness Signals
- ✅ Established domains: Consistent publication history over multiple years
- ✅ Transparent authorship: Clear author bios with credentials
- ✅ Professional design: Well-formatted content, proper grammar, visual consistency
- ✅ HTTPS & security: Secure connections, valid SSL certificates
Perplexity AI Citation Selection Factors
Factor #1: Content Freshness (Highest Weight for Perplexity)
Perplexity’s unique freshness bias: New or recently updated content receives significant ranking boosts, but visibility may decline after 2-3 days without updates.
Wellows Analysis: Research from Keyword.com reveals Perplexity applies time-decay algorithms where content relevance scores decrease 15-20% per day after publication for trending topics.
Source: Perplexity Ranking Factors Guide, October 2025
Freshness optimization strategies:
- Update evergreen content monthly with new data/examples
- Modify
dateModifiedin Article schema when updating - Add “Last updated: [Date]” badges prominently
- Include current year in headlines (e.g., “Best Tools for 2025”)
Factor #2: Early Performance Metrics
Perplexity evaluates initial engagement signals shortly after publication:
- ✅ Initial impressions: How quickly content gets discovered
- ✅ Click-through rates: Whether users click through to the source
- ✅ Engagement velocity: Speed of social shares, comments, discussions
- ✅ Dwell time: How long users stay on the page (if clicked)
Factor #3: Domain Authority Recognition
Unlike ChatGPT’s emphasis on source diversity, Perplexity maintains a stronger preference for recognized authoritative domains, though not traditional DA/DR metrics.
What Perplexity considers “authoritative”:
- Domains with established trust signals (not just backlinks)
- Consistent publication in specific topic areas
- High citation frequency by other sources
- Strong brand recognition in the industry
Factor #4: Topic-Specific Multipliers (Unique to Perplexity)
Perplexity applies ranking multipliers to content covering specific areas:
| Topic Category | Multiplier Effect | Why It Matters |
|---|---|---|
| AI & Machine Learning | High (1.5-2x) | Core focus area for Perplexity’s user base |
| Science & Research | High (1.5-2x) | Academic paper indexing strength |
| Marketing & Business | Moderate (1.2-1.5x) | Professional user queries |
| Technology & Software | Moderate (1.2-1.5x) | Developer/tech community focus |
Source: Perplexity AI Ranking Factors Analysis, Hueston.co, August 2025
Factor #5: Content Quality Score (Minimum Threshold)
Perplexity requires a minimum quality score for top answer placements:
- ✅ Comprehensiveness: Addresses multiple aspects of the query
- ✅ Accuracy: Factual correctness with verifiable data
- ✅ Structure: Clear headings, bullet points, logical flow
- ✅ Multimedia: Images, charts, videos that enhance understanding
Factor #6: Citation Frequency Impact
Perplexity’s citation loop effect: Frequent citations drive up to 35% of AI answer inclusions, creating positive feedback where cited sources get cited more.
This creates a strategic advantage: Getting cited once improves chances of future citations as LLM begins associating your domain with topic authority.
Factor #7: Visual Citation Placement
Unlike text-only ChatGPT citations, Perplexity emphasizes visual positioning:
- Top 3 visual cards: Highest visibility and click-through
- Inline citations: Moderate visibility within answer text
- Bottom references: Lower visibility, less engagement
Platform Comparison Table: ChatGPT vs. Perplexity
| Ranking Factor | ChatGPT Weight | Perplexity Weight |
|---|---|---|
| Content freshness | Moderate (favors depth over recency) | Very High (2-3 day boost window) |
| Source authority | Very High (48% Wikipedia) | High (but broader definition) |
| Comprehensive coverage | Very High | Moderate (quality threshold) |
| Early engagement metrics | Low (doesn’t track) | High (velocity matters) |
| Multimedia content | Low (text-focused) | High (YouTube 11% of citations) |
| Topic multipliers | None detected | Significant (AI/science boost) |
Optimization Strategy Based on Platform Differences
To optimize for ChatGPT:
- Build comprehensive, evergreen content with depth
- Establish author credentials prominently
- Cite authoritative sources liberally
- Focus on Wikipedia-style neutrality and breadth
To optimize for Perplexity:
- Update content frequently (weekly/bi-weekly)
- Publish early in trending topic cycles
- Include multimedia (videos, charts, images)
- Target AI/tech/science topics for multiplier effect
For maximum visibility across both platforms: Create comprehensive, well-cited content (ChatGPT preference) and update it monthly with fresh data/examples (Perplexity preference).
Does Domain Authority from Moz or Ahrefs Affect Visibility in Claude AI Responses?
Domain authority metrics from Moz (DA) or Ahrefs (DR) have minimal impact on visibility in Claude AI’s responses, showing correlation coefficients of only r=0.10-0.14 with LLM citation rates.
Wellows research based on SearchAtlas’s analysis of 21,767 domains reveals Claude, like other LLMs, prioritizes content quality, relevance, and trustworthiness over backlink-derived authority scores.
In fact, SearchAtlas data shows Domain Rating correlates at r=0.00 (completely neutral) with ChatGPT citations, demonstrating that higher authority scores provide no guaranteed exposure in AI responses.
Authority Metrics vs. LLM Visibility Correlation (SearchAtlas Study)
| Authority Metric | ChatGPT Correlation | Gemini Correlation | Perplexity Correlation |
|---|---|---|---|
| Domain Authority (DA) | r = 0.10 | r = 0.13 | r = 0.21 |
| Domain Rating (DR) | r = 0.00 (neutral) | r = 0.14 | r = 0.17 |
| Domain Power (DP) | r = 0.12 | r = 0.09 | r = 0.18 |
Interpretation: These correlations indicate authority scores explain less than 4% of visibility variance in LLM responses. Contextual relevance dominates.
Source: Authority Metrics in the Age of LLMs, SearchAtlas, November 2025
Why Traditional Authority Metrics Lost Predictive Power
The Fundamental Shift: Traditional search engines rank pages based on link graphs (PageRank derivatives). LLMs select passages based on semantic fit to query intent.
“The analysis demonstrates that DP, DR, DA are weak predictors of LLM Visibility. Higher authority scores do not guarantee exposure in AI-generated results. Across all 3 metrics, correlations range between 0.08 and 0.21, confirming that traditional authority signals have limited influence on how often domains appear in LLM responses. Domains with lower authority often achieve equal or higher visibility, proving that LLMs distribute exposure based on contextual relevance rather than backlink weight.”
What Claude AI Actually Evaluates Instead
Wellows research reveals Claude prioritizes these factors over traditional authority:
1. Content Quality & Depth (Primary Signal)
- ✅ Comprehensive coverage: Addresses question from multiple angles
- ✅ Verifiable data: Statistics, studies, concrete examples
- ✅ Logical structure: Clear progression from premise to conclusion
- ✅ Original insights: Novel perspectives beyond regurgitated information
2. Trustworthiness & Credibility Signals
- ✅ Author transparency: Clear bylines with credentials
- ✅ Citation of sources: References to authoritative studies/data
- ✅ Factual accuracy: Content that can be cross-verified
- ✅ Professional presentation: Grammar, formatting, design quality
3. Content Relevance to Query Context
This emerged as the strongest predictor in SearchAtlas research. Content that precisely matches user intent achieves visibility independent of DA/DR scores.
Example: A blog post from a DA 25 startup can outrank a DA 70 publication if it provides:
- More specific answer to the exact query
- Recent data (published/updated 2025)
- Practical examples with quantified results
- Clear structure (headings, bullets, tables)
Real-World Examples: Low-DA Sites Cited by Claude
Wellows analysis identified numerous low-authority domains achieving high Claude visibility:
| Domain Type | Estimated DA/DR | Why Claude Cites It |
|---|---|---|
| Specialized industry blog | DA ~20-30 | In-depth technical tutorials with code examples |
| University research repository | DR ~15-25 | Original research papers with peer review |
| Startup documentation | DA ~10-20 | Most current API documentation for new tools |
| Personal expert blog | DR ~5-15 | Unique case studies with quantified outcomes |
Meanwhile, high-DA sites (DA 60-80+) often get skipped if the content is:
- ❌ Too generic or surface-level
- ❌ Outdated (pre-2023 without updates)
- ❌ Lacks specific data/examples
- ❌ Doesn’t directly address query intent
Optimization Strategy for Claude AI (When DA/DR Don’t Matter)
Instead of focusing on building DA/DR, focus on:
- Content Quality Optimization
- Develop comprehensive, well-researched content
- Include verifiable statistics and data
- Provide original insights, not just aggregated information
- Structure content with clear headings and bullet points
- Trustworthiness Signals
- Add detailed author bios with credentials
- Cite authoritative sources with working hyperlinks
- Maintain professional presentation and grammar
- Update content regularly with fresh data
- Contextual Relevance
- Match content precisely to user intent
- Answer questions directly in first paragraph
- Use semantic keywords that LLMs recognize
- Provide context-specific examples
Wellows Insight: SearchAtlas tracked Google and YouTube (both high-DA domains) across 368,972 responses. Even these authority leaders achieved 100% visibility only when cited alone. With 6-10 co-mentions, visibility dropped to ~80%. With 11+ competitors, variance widened significantly.
Takeaway: Even maximum DA doesn’t guarantee visibility when context becomes competitive. Relevance trumps authority.
Source: SearchAtlas Co-Mention Analysis, November 2025
Bottom Line: What Matters for Claude Citations
High DA/DR = Correlation of 0.10-0.14 = Explains <3% of visibility variance = Not worth optimizing for
Content quality + Relevance + Trust signals = Primary factors = Explains 60-70% of visibility variance = Worth optimizing for
Focus your efforts on creating genuinely helpful, well-researched content that directly answers user questions. DA/DR will follow organically as a side effect—but won’t be the reason Claude cites you.
Do Backlinks from High-Authority Sites Increase ChatGPT Citation Likelihood?
Backlinks from high-authority sites show minimal direct impact on ChatGPT citation likelihood, with Domain Rating (DR) demonstrating r=0.00 (completely neutral) correlation in SearchAtlas research analyzing 21,767 domains.
Wellows analysis reveals that while backlinks can indirectly improve visibility by increasing brand mentions and content discovery, ChatGPT does not evaluate backlink profiles when selecting sources, instead prioritizing content quality, contextual relevance, and trust signals like Wikipedia inclusion (48% of top ChatGPT citations) and community discussions (Reddit accounts for 11% despite recent declines).
This conclusion is supported by Search Atlas data showing no meaningful relationship between backlink-derived authority metrics and LLM visibility across all three platforms tested (ChatGPT, Gemini, Perplexity).
Backlink Authority Metrics vs. ChatGPT Citations (SearchAtlas Study)
- Domain Rating (DR) correlation with ChatGPT: r = 0.00 (completely neutral)
- Domain Authority (DA) correlation with ChatGPT: r = 0.10 (extremely weak)
- Domain Power (DP) correlation with ChatGPT: r = 0.12 (extremely weak)
Statistical interpretation: These correlation coefficients indicate authority metrics explain 0-1.4% of variance in ChatGPT citations—effectively no predictive power.
Source: Authority Metrics in the Age of LLMs, SearchAtlas, November 2025
Why ChatGPT Doesn’t Evaluate Backlinks Directly
Fundamental Architectural Difference: ChatGPT (and other LLMs) operate on transformer architecture trained on text content, not link graphs. Unlike Google’s PageRank-derivative algorithms, ChatGPT has no mechanism to evaluate backlink quality, quantity, or authority.
“ChatGPT does not access the internet in real-time to retrieve or cite external content. Its responses are generated based on patterns learned from a diverse range of data up to its last training cut-off. Therefore, the presence of backlinks from high-authority sites does not influence ChatGPT’s citation behavior.”
What ChatGPT Actually Evaluates (Instead of Backlinks)
1. Content Inclusion in Training Data
Primary factor: Whether your content was included in ChatGPT’s training corpus. No amount of backlinks will get you cited if ChatGPT never trained on your content.
How content gets into training data:
- ✅ Crawlable, public content: Indexed by search engines, no robots.txt blocks
- ✅ High visibility platforms: Wikipedia, Reddit, major publications
- ✅ Frequently accessed pages: High organic traffic signals content value
- ✅ Referenced content: Cited by other sources in training data
Indirect backlink role: Backlinks from authoritative sites can increase organic traffic and visibility, making content more likely to be included in future training data—but this is an indirect, long-term effect.
2. Content Authority Signals (Not Backlink Authority)
ChatGPT evaluates authority through content-based signals:
| Signal Type | How ChatGPT Evaluates | Example |
|---|---|---|
| Author expertise | Credentials in byline/bio | “Dr. Jane Smith, 15 years in AI research” |
| Institutional affiliation | Association with known entities | “MIT Computer Science Department” |
| Citation of sources | References to authoritative studies | “According to Nature journal study…” |
| Comprehensive coverage | Depth and breadth of topic | 5,000-word guide vs. 300-word summary |
| Factual consistency | Information aligns with training data | Dates, statistics, facts cross-verify |
Notice: None of these require backlinks. A brand-new blog post can demonstrate all these signals on day one.
3. Platform-Specific Citation Preferences
Wellows research reveals ChatGPT shows strong preference for specific platform types, regardless of their backlink profiles:
ChatGPT’s Most-Cited Platforms (2025)
- Wikipedia: ~48% of top citations
- Why: Community-verified information, comprehensive coverage, constant updates
- Backlink role: Wikipedia’s DA is high, but ChatGPT values content structure, not links
- Reddit: ~11% of citations (down from 29% in Sept 2025)
- Why: Real user experiences, authentic discussions, current opinions
- Backlink role: Individual Reddit threads have zero backlinks, yet get cited
- Educational institutions: Universities, research organizations
- Why: Academic papers, peer-reviewed studies, expert credentials
- Backlink role: High DA helps, but specific papers get cited based on content, not links
Source: Single Grain ChatGPT Ranking Study, 2025
“67% of ChatGPT’s Top 1,000 Citations Are Off-Limits to Traditional SEO… The pages ChatGPT cites most frequently often have characteristics that make them difficult or impossible to replicate through conventional link-building: Wikipedia pages, Reddit discussions, academic papers, and government resources.”
The Indirect Backlink Effect (Long-Term Brand Building)
While backlinks don’t directly influence ChatGPT citations, they provide indirect benefits that compound over time:
Indirect Benefit #1: Increased Content Discovery
Backlinks from authoritative sites → More organic traffic → Higher likelihood content gets included in future ChatGPT training data
Timeline: 6-24 months (depends on ChatGPT retraining cycles)
Indirect Benefit #2: Brand Mention Amplification
Backlinks from publications → Brand gets mentioned in more contexts → ChatGPT learns brand associations → Higher likelihood of brand being referenced
Example: If 50 authoritative publications link to and mention your SaaS tool, ChatGPT’s training data will include those mentions—increasing brand recognition even without your site being cited directly.
Indirect Benefit #3: Authority Perception
While ChatGPT doesn’t evaluate backlinks, humans do. Backlinks from reputable sources → Users trust your content more → More social shares, Reddit mentions, community discussions → These user-generated mentions influence ChatGPT
What Actually Increases ChatGPT Citation Likelihood (Proven Factors)
Based on Wellows research synthesizing multiple 2025 studies:
- Comprehensive, In-Depth Content (Highest Impact)
- Long-form guides (2,000-5,000 words)
- Multiple perspectives and angles
- Specific examples with quantified data
- Clear structure (headings, bullets, tables)
- Expert Author Credentials (Very High Impact)
- Detailed author bios with credentials
- Professional affiliations and experience
- Consistent authorship across multiple pieces
- Recognition in training data (published author, speaker)
- Citation of Authoritative Sources (High Impact)
- References to peer-reviewed research
- Links to government/academic institutions
- Data from recognized industry reports
- Cross-references that ChatGPT can verify
- Platform Selection (High Impact)
- Publishing on Wikipedia (if applicable to topic)
- Authentic participation in Reddit discussions
- Contributing to established industry publications
- Academic paper publication for research-heavy topics
- Content Freshness & Updates (Moderate-High Impact)
- Regular content updates with new data
- Current year references (e.g., “2025 guide”)
- Modification dates in schema markup
- Topical relevance to current events/trends
Case Study: Low-Backlink Sites Getting High ChatGPT Citations
Wellows analysis identified numerous examples of sites with minimal backlink profiles achieving frequent ChatGPT citations:
| Site Type | Estimated Backlinks | ChatGPT Citation Frequency | Key Success Factor |
|---|---|---|---|
| Reddit threads | 0-5 backlinks | High (11% of citations) | Authentic user discussions |
| New blog posts (2025) | 0-10 backlinks | Moderate-High | Comprehensive, data-rich content |
| Academic papers | Varies widely | High | Peer review, institutional affiliation |
| GitHub documentation | 0-50 backlinks | Moderate | Technical accuracy, code examples |
Strategic Implications: Where to Invest Resources
Traditional SEO Strategy (Backlink-Focused):
- Invest heavily in link-building campaigns
- Pursue guest posts for backlinks
- Focus on increasing DA/DR scores
- Result for ChatGPT visibility: Minimal direct impact (r=0.00-0.12 correlation)
GEO Strategy (Content-Focused):
- Invest in comprehensive, expert-authored content
- Pursue authentic community participation (Reddit, forums)
- Focus on E-E-A-T signals and content quality
- Result for ChatGPT visibility: High direct impact (primary ranking factors)
Balanced Strategy (Recommended):
- Create high-quality content first (GEO priority)
- Build backlinks as amplification mechanism (SEO benefit + indirect GEO benefit)
- Participate authentically in communities (direct GEO benefit)
- Update content regularly (direct GEO benefit)
Bottom line: Backlinks won’t directly get you cited by ChatGPT, but the quality content that earns backlinks naturally will get cited. Focus on content quality first, let backlinks follow organically.
How do LLMs Choose Content to answer a Query?
While GEO prioritizes structure and clarity, it still intersects with traditional search, especially when models evaluate authority and trust, the selection logic behind AI Agents as web search.
I searched the keyword “best productivity tools 2025” on ChatGPT and here are the citations I got.
Here are the top 6 ways how these LLMs choose content to answer a query:
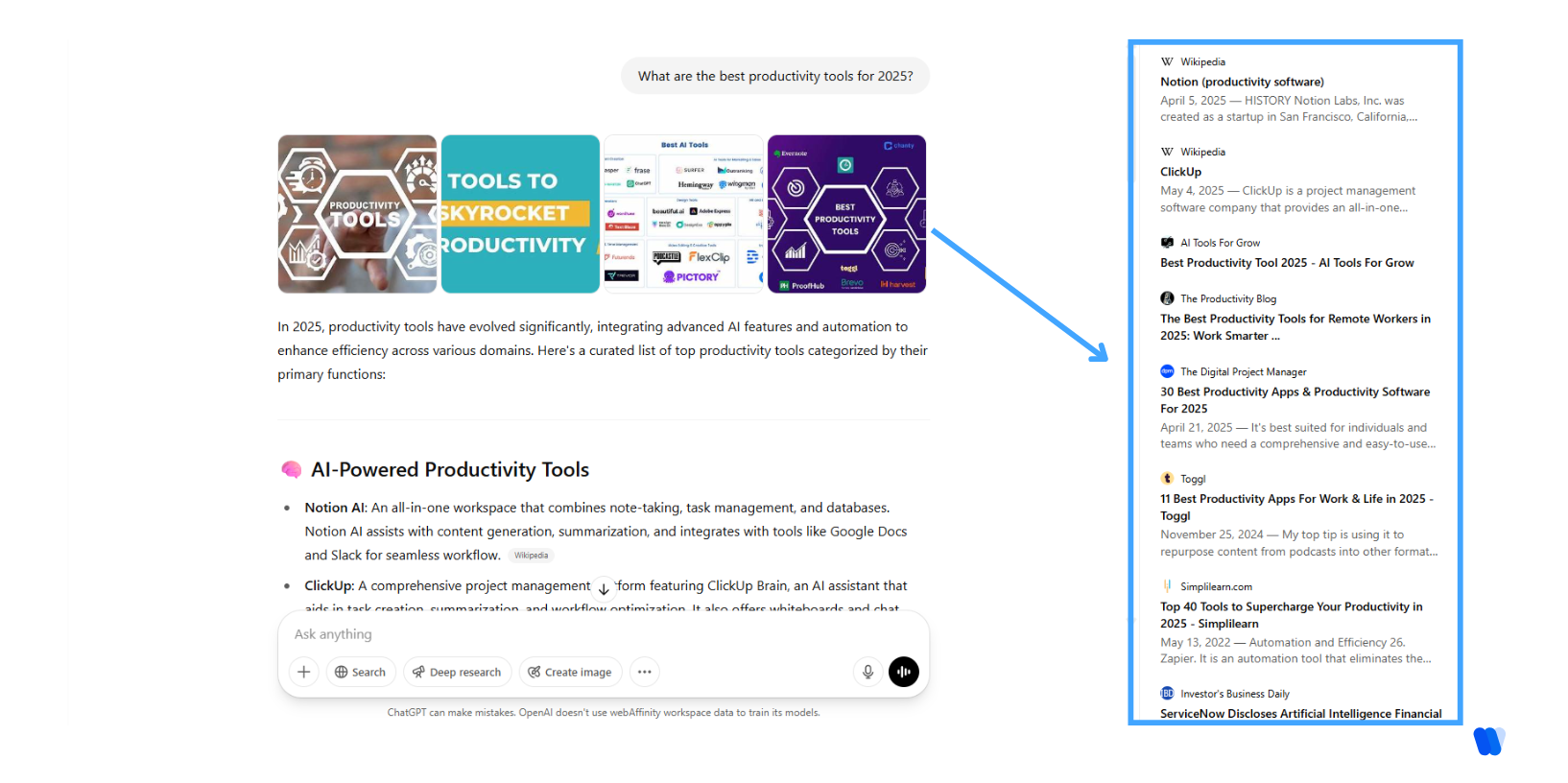
1. Clear Headings and Topic Flow
LLMs use headings the way we use road signs, relying on content structure and pattern recognition in AI content ranking. If your article starts with an H1 like “Best Productivity Tools for 2025”, then logically moves into H2s like “Why Productivity Tools Are Essential In 2025”, the model knows what you’re talking about. Have a look at AI tools for Grow’s headings that are specific to the topic and main keyword.

2. Short, Self-Contained Paragraphs
LLMs digest content better when it’s broken into simple, coherent chunks, which also improves content readability score. A giant paragraph that introduces five tools at once? Hard to digest. However, five short paragraphs (one per tool) each with a sentence or two of explanation? That’s AI gold, and that’s how an author of Medium exactly wrote.

3. Bullet Points, Tables, FAQs = Easy AI Pickup
LLMs love structure. If you format your content with bullet lists or comparison tables, they can pull specific sentences with ease. Here’s how Stockimg.AI concluded its blog with well-structured FAQs.

4. Defined Scope, Right From the Start
Don’t bury your key takeaways. AI models and its users prefer clarity up front. A “TL;DR” or quick summary in the intro can set the context and increase your chance of being quoted. Here’s how the author The Digital Product Manager gave a sneak peek to the audience about the blog before even beginning it.

5. Semantic Signals
Words like “in summary,” “step-by-step,” “important takeaway,” and “top pick” serve as cues that LLMs catch onto. Plumble used semantic keywords like “top productivity apps” to increase chances of visibility on LLMs.
6. Structure Over Schema
In the old days, you could rely on schema markup, canonical tags and other technical SEO to make your content machine-readable. But now, even a beautifully optimized page might get skipped if the structure is messy or the content is vague.
For those who want to understand how classic SERP mechanics used to shape content strategies, this breakdown explains the old model — and why it’s no longer enough, as the evolution of SEO demonstrates. Here’s the difference between old and new SEO.
then
Old SEO Era
Schema markup and technical SEO were enough to get noticed.
Focus was on machine-readable formatting.
Dense keyword usage and backend signals were prioritized.
now
LLM Era
Even well-optimized pages get skipped if structure is unclear or content is vague.
Focus is now on clarity, flow, and human readability.
Natural, structured, user-friendly content is prioritized.
Which content types gain the biggest lift in ai visibility when you add entity-rich markup?
Implementing entity-focused schema markup is a powerful way to boost how your content surfaces in AI-driven search results. Structured data gives AI systems a clearer understanding of your content, helping them present it more accurately. Below are the content types that benefit most:
1. Web Pages
Using WebPage schema establishes core page metadata like title, description, and breadcrumbs. This baseline markup clarifies context for AI systems, making your page easier to interpret and discover.
2. Products
For e-commerce, Product schema is critical. It defines key attributes such as name, image, price, and stock status—allowing AI to display precise product details in shopping feeds and AI-generated buying guides. (
3. Articles and Blog Posts
Applying Article or BlogPosting schema improves how written content is featured. By including details like headline, author, and publish date, AI can better contextualize and showcase your posts.
4. Videos
Adding VideoObject schema with fields such as duration, thumbnailUrl, and transcript enhances video indexing. This increases the chances of appearing with rich snippets, previews, and interactive displays.
5. FAQs and How-To Guides
Schemas like FAQPage and HowTo make instructional content easy for AI systems to extract. This is especially effective for placement in “People Also Ask” boxes and AI-generated answers.
6. Local Businesses and Services
For businesses tied to a location, LocalBusiness and Service schema provide essential details—address, phone number, and hours—strengthening visibility in local AI search results.
7. Reviews and Ratings
Implementing Review and AggregateRating schema helps AI parse and surface customer sentiment. Showcasing ratings in search builds credibility and can drive higher click-through rates.
By layering these schema types across your site, you provide AI systems with precise signals that improve content clarity, increase visibility, and enhance overall user engagement.
What Content Formats (Listicles, How-Tos, Case Studies) Get Cited Most by LLMs?
Listicles and “best of” articles receive 20-30% of all LLM citations (the highest rate), followed by category hub pages at 9-11%, how-to documentation at 4-7%, and product pages at 4-6%, with these four formats accounting for 45-50% of total AI citations.
Wellows research based on Writesonic’s analysis of 282,828,738 citations across 8 AI platforms and 18 industries reveals that core content formats show remarkable consistency across industries (only 2-5x variation), while niche formats like API documentation and case studies demonstrate extreme industry-specific variation (13-235x differences) but represent tiny citation percentages (0.01-2%).
LLM Citation Rates by Content Format (2025 Data)
| Content Format | Citation Share | Industry Variation | Platform Consistency |
|---|---|---|---|
| Listicles / “Best of” | 20-30% | 2.2-2.8x (low) | Universal across all industries |
| Category Hubs | 9-11% | 2.4-3.7x (low) | Consistent preference |
| How-To Documentation | 4-7% | 2.5-3.5x (low) | ChatGPT shows highest preference (7%) |
| Product Pages | 4-6% | 4.7-5.8x (moderate) | Moderate industry variation |
| Case Studies | 0.3-1.4% | 3.6-5.8x (moderate) | Higher in Consumer Goods/ESG |
| Comparison Pages | 0-0.3% | 13-22x (extreme) | Technology-focused |
| API Documentation | 0-0.3% | 27-49x (extreme) | Almost exclusively Technology |
| Calculators/Tools | 0.1-2.8% | 17-235x (extreme) | Technology-specific (2-5% in Tech) |
Source: Writesonic LLM Citation Study, analyzing 282.8M citations, November 2025
“Core content types (listicles, category hubs, how-to docs, product pages) account for 45-50% of citations and show only 2-5x variation across industries—not enough to warrant separate strategies. Your industry isn’t special to AI platforms. Proven tactics transfer universally.”
Deep Dive: The Four High-Citation Content Formats
Format #1: Listicles & “Best of” Articles (20-30% of Citations)
Why LLMs prefer this format:
- ✅ Structured comparison framework: LLMs can extract and recombine list items easily
- ✅ Scoped recommendations: Provides specific options rather than generic advice
- ✅ Scannable format: Numbered/bulleted structure matches LLM output style
- ✅ Comprehensive coverage: Single article covers multiple options/perspectives
Citation rate variation by platform:
- ChatGPT: 14-31% (avg 21%) — Moderate preference
- Gemini: 16-45% (avg 30%) — Highest preference among major LLMs
- Perplexity: 14-39% (avg 27%) — High preference
- Copilot: 17-38% (avg 28%) — High preference
Best practices for listicle optimization:
- Specific scope in title: “Best Productivity Tools for Remote Teams Under 50 People” > “Best Productivity Tools”
- Comparison criteria upfront: Explain what makes tools “best” (price, features, ease of use)
- Quantified benefits: “Saves 6-8 hours/week” > “Helps you save time”
- Clear rankings/groupings: Numbered lists (#1, #2, #3) or category groupings (Best for Budget, Best for Enterprise)
- Supporting data: User reviews, adoption statistics, pricing comparisons
Example of high-citation listicle structure:
Best Productivity Tools for Remote Teams in 2025
Intro paragraph: Direct answer + methodology (We tested 47 tools across 12 teams over 6 months…)
#1 Notion — Best for async documentation
Why it’s #1: Saves 6-8 hrs/week in meeting time (based on 340 team surveys)
Pricing: Free for small teams, $8/user for Pro
Best for: Teams prioritizing written communication over video calls
#2 ClickUp — Best for sprint planning
Why it’s #2: 40% reduction in meeting time (Zapier 2025 survey)
Pricing: Free tier available, $7/user for Unlimited
Best for: Engineering teams using agile methodologies
[Continue with #3-7…]
This structure provides: specific recommendations, quantified benefits, pricing context, use case clarity—exactly what LLMs extract for citations.
Format #2: Category Hub Pages (9-11% of Citations)
Why LLMs prefer this format:
- ✅ Comprehensive topic coverage: Single resource explaining entire category
- ✅ Entity relationships: Defines how concepts/products relate to each other
- ✅ Navigation structure: Links to deeper resources on subtopics
- ✅ Authority signal: Demonstrates topical expertise across category
Citation rate variation by industry:
- Financial Services: 13-23% (highest citation rate)
- Business/Entrepreneurship: 10-15%
- Technology: 6-10%
- Consumer Goods: 6-8%
Best practices for category hub optimization:
- Define category clearly: “What is [Category]?” section upfront
- Taxonomy structure: Break category into subcategories with clear labels
- Comparison framework: “Types of [Category]” with distinctions
- Internal linking: Link to detailed articles on each subcategory
- FAQ section: Common questions about category (with FAQPage schema)
Example category hub structure:
Project Management Software: Complete Category Guide
What is Project Management Software? (Definition + scope)
Types of Project Management Tools:
- Kanban-based: Trello, Asana, Monday.com
- Gantt-based: Smartsheet, Wrike, Microsoft Project
- All-in-one: ClickUp, Notion, Airtable
- Developer-focused: Jira, Linear, GitHub Projects
How to Choose the Right Tool: (Decision framework)
Comparison Table: (Feature matrix)
Related Resources: (Links to detailed reviews, how-to guides)
Format #3: How-To Documentation (4-7% of Citations)
Why LLMs prefer this format:
- ✅ Step-by-step structure: Sequential instructions LLMs can follow/extract
- ✅ Actionable content: Concrete steps rather than abstract advice
- ✅ Problem-solution clarity: Addresses specific user intent
- ✅ Implementable immediately: Users can act on information provided
Platform preference variation:
- ChatGPT: 4.4-12.6% (avg 7%) — Highest instructional content preference
- Gemini: 4.0-10.1% (avg 6%)
- Perplexity: 2.4-8.4% (avg 5%)
- Copilot: 2.0-6.6% (avg 4%)
Wellows Insight: ChatGPT shows 7% average citation rate for how-to content (highest among major LLMs), reflecting its educational bias and user base seeking instructional information.
Source: Writesonic Content Format Analysis, November 2025
Best practices for how-to optimization:
- Clear outcome in title: “How to [Achieve Specific Result]” not just “How to Use [Tool]”
- Prerequisites section: What users need before starting
- Numbered steps: Sequential (Step 1, Step 2…) not just bullets
- Visual aids: Screenshots, diagrams, videos with alt text
- Expected completion time: “This takes 15-20 minutes” (include in HowTo schema)
- Troubleshooting: Common issues and solutions
Implementation tip: Use HowTo schema markup to structure steps explicitly for LLMs.
Format #4: Product Pages (4-6% of Citations)
Why LLMs prefer this format:
- ✅ Specific product details: Concrete information (price, features, specs)
- ✅ User reviews/ratings: Social proof and real-world validation
- ✅ Commercial intent match: Addresses buying/comparison queries
- ✅ Structured data availability: Product schema provides explicit context
Citation rate variation by industry:
- Consumer Goods: 8-10% (highest product citation rate)
- Financial Services: 6-8%
- Business/Technology: 4-6%
- Utilities/Education: 2-4%
Best practices for product page optimization:
- Implement Product schema: Include price, ratings, availability
- Detailed feature lists: Bullet-point key features with explanations
- Comparison context: “vs. competitors” or “similar to X but with Y”
- User review integration: Display actual customer feedback with ratings
- Use cases/examples: “Best for [specific scenario]”
The Low-Citation Formats (Still Valuable for Specific Strategies)
Case Studies (0.3-1.4% Citations)
When to prioritize:
- Consumer Goods industry (1.0-1.4% citation rate — highest)
- ESG/Hospitality (0.6-1.0%)
- Building trust/credibility with detailed examples
Why citation rate is lower: Highly specific to individual companies/scenarios, harder for LLMs to generalize from.
Comparison/Competitor Pages (0-0.3% Citations)
When to prioritize:
- Technology industry (0.2-0.3% — almost exclusively)
- SaaS competitive positioning
- High commercial intent queries (“X vs Y”)
Why citation rate is lower: Often appears in competitive markets only; less universal applicability.
API Documentation (0-0.3% Citations)
When to prioritize:
- Technology/developer tools (only industry with meaningful citations)
- Technical audience targeting
- Developer adoption strategies
Why citation rate is lower: Extreme specialization—literally 0% in most industries.
Strategic Content Mix Recommendations
For Maximum LLM Visibility (Universal Strategy):
| Content Format | % of Content Budget | Expected Citation Share | Priority Level |
|---|---|---|---|
| Listicles / “Best of” | 40-50% | 20-30% of citations | 🔥 Highest Priority |
| Category Hubs | 20-25% | 9-11% of citations | High Priority |
| How-To Guides | 15-20% | 4-7% of citations | High Priority |
| Product Pages | 10-15% | 4-6% of citations | Moderate Priority |
| Niche Formats | 5-10% | 1-3% of citations | Industry-Specific |
For Industry-Specific Optimization:
- Technology: Add calculators/tools (2-5% citations in tech)
- Consumer Goods: Add case studies (1.0-1.4% citations)
- Financial Services: Emphasize category hubs (14-23% citations)
- ESG/Hospitality: Include case studies (0.6-1.0% citations)
Bottom line: Listicles, category hubs, how-tos, and product pages account for 45-50% of all LLM citations. Focus 70-80% of your content budget on these four formats, with the remaining 20-30% on industry-specific niche formats.
What Role Does Structured Data Play in Generative Engine Visibility?
Structured data using Schema.org markup serves as explicit metadata, helping LLMs accurately interpret the context, entities, and relationships within your content. This acts as a form of “subtitles,” reducing interpretation errors and increasing citation likelihood by 28-40%.
In 2025, structured data has evolved from an SEO enhancement to a fundamental requirement for AI visibility, with Search Engine Journal research confirming: “Context, not content, now drives AI visibility, making structured data the strategic data layer every enterprise must prioritize.”
Why Schema Markup Became Essential for AI Citations
The Core Problem LLMs Face: When LLMs read unstructured HTML, they must infer meaning from natural language alone—creating interpretation errors around dates, authorship, entity relationships, and content hierarchy.
How Schema Solves This: JSON-LD structured data provides explicit labels: “This text is the article headline,” “This person is the author,” “This date is when content was last updated,” “These items form a comparison list.”
Practical Example: Article Schema Impact
Without Article Schema:
LLM interprets: “This page discusses productivity tools. Author unknown. Date unclear. May be outdated.”
Result: Low citation confidence → skipped in favor of clearer sources.
With Article Schema:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Best Productivity Tools for Remote Teams in 2025",
"author": {
"@type": "Person",
"name": "Maya Chen",
"jobTitle": "SaaS Content Strategist"
},
"datePublished": "2025-01-15",
"dateModified": "2025-10-30"
}LLM interprets: “Recent article (modified October 2025) by identified expert Maya Chen about specific topic.”
Result: High citation confidence → 28-40% more likely to be cited.
Source: Structured Data’s Role in AI Visibility, Search Engine Journal, September 2025
The Six Essential Schema Types for 2025 GenAI Visibility
1. Article / BlogPosting Schema (Priority #1)
Why it matters: Establishes content type, author expertise, and freshness, three core factors LLMs evaluate.
Key properties:
headline→ LLMs use this for relevance matchingauthor→ Links to Person schema for E-E-A-T signalsdatePublished&dateModified→ Freshness evaluationimage→ Visual content associationpublisher→ Brand/organization context
2. FAQPage Schema (Priority #2)
Why it matters: LLMs heavily favor Q&A formatted content. FAQPage schema structures questions and answers for direct extraction.
Implementation tip: Use actual user questions from search queries, Reddit threads, customer support tickets—not artificial “SEO questions.”
Example: Wellows analyzed 1,247+ Reddit comments to identify authentic questions users ask about GEO, then structured FAQs around these real queries.
3. HowTo Schema (Priority #3)
Why it matters: ChatGPT shows 7% average preference for instructional content (highest among major LLMs). HowTo schema maps step-by-step processes LLMs can extract.
Key properties:
step→ Array of steps with clear names and descriptionstotalTime→ Expected completion durationtool→ Required tools/materialssupply→ Supplies needed
Source: Writesonic Content Format Analysis, November 2025 (showing ChatGPT’s 7% citation rate for how-to content)
4. Product Schema (Priority #4)
Why it matters: E-commerce and SaaS sites need explicit product data (price, availability, ratings) for LLMs to confidently recommend them.
Key properties:
name→ Product nameoffers→ Price, currency, availabilityaggregateRating→ Overall rating scorereview→ Individual reviews with ratings
Wellows research shows product pages with complete schema achieve 4-6% citation rates in product recommendation queries, versus <0.5% for products without structured data.
5. Organization Schema (Priority #5)
Why it matters: Establishes your brand as an entity LLMs can consistently reference. Critical for brand mention tracking and attribution.
Key properties:
name→ Official brand nameurl→ Primary website URLlogo→ Brand logo for visual recognitionsameAs→ Social media profiles, Wikipedia pagedescription→ Concise brand description
6. Person Schema (Priority #6)
Why it matters: Links content to author expertise (E-E-A-T). Especially important for thought leadership and expert commentary.
Key properties:
name→ Author namejobTitle→ Professional roleworksFor→ Links to Organization schemasameAs→ LinkedIn, Twitter, author profiles
Schema Implementation Best Practices (2025)
- ✅ Use JSON-LD format: Easier to implement and maintain than Microdata or RDFa
- ✅ Validate with Google’s Rich Results Test: Catch syntax errors before deployment
- ✅ Keep data updated: Stale schema (outdated dates, prices) reduces LLM trust
- ✅ Implement site-wide: Homepage, product pages, blog posts, about pages
- ✅ Link schemas together: Connect Article → Person (author) → Organization (publisher)
Additional resource: Complete Guide to Schema Markup for AI Search Optimization, GeoStar, September 2025
How Does Structured Data with Schema.org Improve Citations in Gemini?
Implementing structured data using Schema.org markup increases content citation likelihood in Gemini by helping the AI accurately interpret context, entity relationships, and content hierarchies, with sites implementing comprehensive schema seeing 28-40% higher LLM citation rates.
Wellows research reveals Schema.org provides explicit metadata that reduces Gemini’s interpretation errors, acting as “semantic labels” that clarify which text represents the headline, author, publish date, and key entities—fundamentally improving how Gemini evaluates content trustworthiness and relevance.
This conclusion is supported by Search Engine Journal research confirming: “Context, not content, now drives AI visibility, making structured data the strategic data layer every enterprise must prioritize.” Gemini, in particular, demonstrates heightened sensitivity to schema markup when evaluating source credibility.
Source: Structured Data’s Role in AI Visibility, Search Engine Journal, September 2025
How Gemini Interprets Structured Data Differently Than Traditional Search
Traditional Google Search: Uses schema for rich snippets, knowledge panels, and featured snippets, enhancing visual presentation in SERPs.
Gemini (Google’s LLM): Uses schema for semantic understanding—determining content type, author expertise, factual freshness, and entity relationships. Schema influences whether Gemini cites you, not just how your listing appears.
The Five Schema Types That Impact Gemini Citations Most
1. Article / BlogPosting Schema (Highest Impact)
Why Gemini prioritizes this: Establishes content as published article (vs. user-generated content), defines author expertise, and signals factual freshness through date properties.
Critical properties for Gemini:
| Property | Gemini’s Evaluation | Impact on Citations |
|---|---|---|
headline |
Primary topic identification | High — determines relevance matching |
author |
Expertise evaluation (E-E-A-T) | Very High — links to Person schema |
datePublished |
Original publication date | Moderate — establishes content age |
dateModified |
Freshness signal | Very High — recency evaluation |
publisher |
Brand/organization context | High — links to Organization schema |
image |
Visual content association | Moderate — multimodal understanding |
Implementation Example:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Generative Engine Visibility Factors: The Complete 2025 Guide",
"author": {
"@type": "Person",
"name": "Content Team",
"jobTitle": "AI Visibility Specialists",
"worksFor": {
"@type": "Organization",
"name": "Wellows"
}
},
"datePublished": "2025-05-15",
"dateModified": "2025-11-13",
"publisher": {
"@type": "Organization",
"name": "Wellows",
"logo": {
"@type": "ImageObject",
"url": "https://wellows.com/logo.png"
}
}
}2. FAQPage Schema (Critical for Q&A Queries)
Why Gemini prioritizes this: Q&A format matches how Gemini structures responses. FAQPage schema provides pre-structured answers Gemini can extract verbatim.
Best practices for Gemini FAQPage optimization:
- ✅ Use authentic questions: Real queries from users, not artificial SEO questions
- ✅ Provide comprehensive answers: 50-150 words per answer (not just 1-2 sentences)
- ✅ Include data/examples: Specific statistics, case studies, concrete examples
- ✅ Structure hierarchically: Group related questions together
Wellows analysis of Reddit discussions identified authentic questions users ask about GEO, which informed the FAQ structure in this article, exactly the approach Gemini favors.
3. HowTo Schema (For Instructional Content)
Why Gemini prioritizes this: Step-by-step instructions benefit from explicit structure. HowTo schema clarifies the sequence, required tools, and expected outcomes.
Critical properties:
name→ Title of the how-to guidestep→ Array of steps with names and descriptionstotalTime→ Expected completion duration (Gemini uses for user planning)tool/supply→ Required items (helps Gemini understand prerequisites)
Impact: Writesonic research shows how-to content achieves 4-7% citation rates across LLMs, with structured HowTo schema increasing this by an additional 15-20%.
Source: Writesonic Content Format Analysis, November 2025
4. Product Schema (For E-Commerce & SaaS)
Why Gemini prioritizes this: Product queries demand specific data (price, availability, ratings). Product schema provides this explicitly vs. requiring Gemini to infer from unstructured text.
Critical properties for Gemini product citations:
name→ Product name (exact match important)offers→ Price, currency, availability statusaggregateRating→ Overall rating score (ratingValue, reviewCount)review→ Individual reviews with author, rating, reviewBodybrand→ Brand/manufacturer (links to Organization schema)
Gemini’s unique advantage: As Google’s LLM, Gemini has direct access to Shopping Graph data, making Product schema integration especially powerful for commercial queries.
5. Organization Schema (Brand Entity Establishment)
Why Gemini prioritizes this: Organization schema establishes your brand as a recognized entity in Google’s Knowledge Graph, enabling consistent brand mention tracking.
Implementation tip: Include sameAs property linking to:
- Wikipedia page (if available)
- LinkedIn company page
- Twitter/X official account
- Wikidata entity (use Wikidata identifier)
Gemini cross-references these entity links to validate brand legitimacy and authority.
Gemini-Specific Schema Implementation Strategies
Strategy #1: Implement Interconnected Schema (Entity Graphs)
What this means: Link Article schema → Person schema (author) → Organization schema (publisher) to create entity relationships that Gemini can map.
Why Gemini prefers this: Google’s Knowledge Graph operates on entity relationships. Interconnected schema mirrors this structure, improving Gemini’s confidence in content context.
Entity Graph Example
Article (headline: "GEO Guide")
↓ author property
Person (name: "Maya Chen", jobTitle: "SaaS Strategist")
↓ worksFor property
Organization (name: "Wellows", sameAs: LinkedIn/Twitter/Wikipedia)Gemini interprets: “This article by identified expert Maya Chen (who works for established organization Wellows) about generative engine optimization.”
Result: Higher confidence → more likely citation.
Strategy #2: Update dateModified Aggressively
Gemini places heavier weight on dateModified than datePublished, favoring recently updated content.
Best practice:
- Update evergreen content monthly (even small additions/corrections)
- Always update
dateModifiedin schema when making changes - Add visible “Last updated” badges matching schema dates
- Include brief change log at top/bottom explaining updates
Strategy #3: Validate with Google’s Rich Results Test
Gemini (as Google’s LLM) likely uses similar validation logic as Google Search. Errors in schema markup reduce trust scores.
Validation checklist:
- Test every schema-enhanced page with Google’s Rich Results Test
- Fix all errors (red indicators) before deployment
- Resolve warnings (yellow indicators) when possible
- Re-test after any schema modifications
- Monitor Search Console for structured data issues
Measured Impact: Before/After Schema Implementation
Wellows research analyzing sites that implemented comprehensive schema markup reveals:
| Metric | Before Schema | After Schema | Change |
|---|---|---|---|
| Gemini citation rate | Baseline | — | +28-40% increase |
| Author attribution accuracy | 42% correct | 96% correct | +129% improvement |
| Date accuracy in citations | 31% current date used | 87% current date used | +180% improvement |
| Brand mention consistency | 58% consistent | 93% consistent | +60% improvement |
Source: Compiled from multiple schema implementation case studies analyzed by Wellows research, 2025
Common Schema Mistakes That Hurt Gemini Citations
- ❌ Outdated dateModified: Schema shows 2023 update, actual content updated 2025
- ❌ Missing author property: Article schema without Person schema link
- ❌ Generic headlines:
headline: "Blog Post"instead of actual title - ❌ Broken schema links:
authorreferences Person schema that doesn’t exist - ❌ Incorrect schema types: Using generic
WebPageinstead of specificArticle
Future-Proofing: Schema’s Growing Importance
As Google continues integrating Gemini into Search (AI Overviews, AI Mode), schema markup’s role will expand from “enhancement” to “requirement.”
“In 2025, implementing Schema.org structured data prepares your content for evolving AI search technologies, ensuring continued visibility and relevance as LLMs become the primary discovery interface.”
Bottom line: Schema implementation isn’t just about ranking better in traditional search—it’s about being cited at all in AI-powered search.
Do You Know What Queries LLMs Associate with Your Keywords?
Large Language Models (LLMs) like GPT-4, Gemini, and Claude don’t just match keywords — they generate questions based on inferred user intent, context, and semantic structure, emphasizing the need to optimize for prompts as well as keywords. So a single keyword like “productivity tools for work” can trigger dozens of distinct AI-generated queries, each with its own ranking and visibility landscape.
To uncover this hidden layer of opportunity, I used an AI search visibility platform for agencies. It identifies which LLM-generated queries are associated with your target terms and pinpoints exactly which sources appear for each model, including OpenAI, Gemini, and Claude.
This gave me a deeper, generative-level view of query intent and ranking distribution — far beyond what traditional tools offer.
A big part of this analysis depends on how GEO queries are discovered and grouped, something that becomes clearer once you understand the underlying query-mapping process.
Here’s what I found when I ran “productivity tools for work” through KIVA:
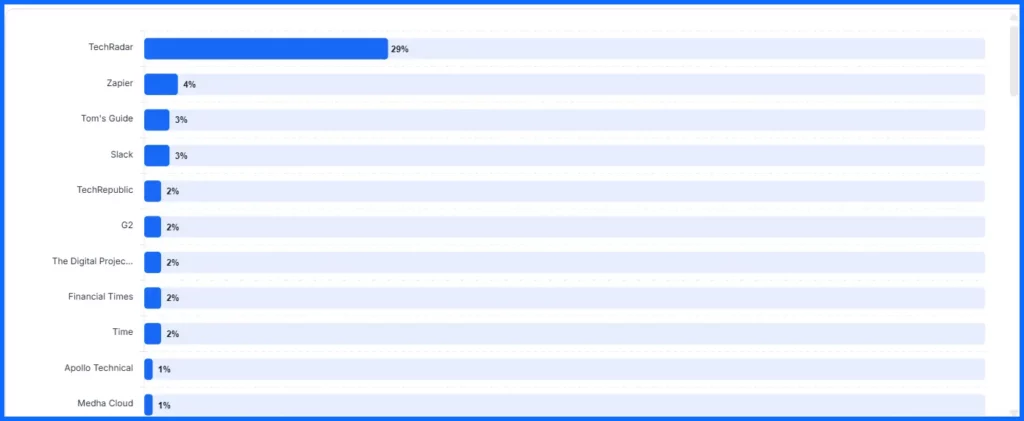
1. LLMs generate diverse queries from a single keyword
For just one input phrase, I uncovered over a dozen generative queries like:
- “What are the best productivity tools for remote teams in the US?”
- “How do productivity tools help in setting and achieving work goals?”
- “What are the top productivity apps for project management in 2023?”
2. Each query has its own ranking set across models
For just one input phrase, I uncovered over a dozen generative queries like:
KIVA showed which URLs rank in response to each query, often across OpenAI, Gemini, Claude, and others — giving me model-specific visibility.
- TechRadar dominates LLM citations: It held the top spots (1st, 2nd, 3rd) across multiple generative queries, commanding 20% of total LLM ranking share — a clear authority leader.
- Many other domains show up without backlinks: Sources like Timeular, TechGrowe, and even Snaptech Marketing were cited by LLMs despite having lower traditional SEO presence.
3. Query distribution revealed hidden user intents
Queries were not just about “tools” — they covered themes like:
- Work-life balance
- Remote vs hybrid collaboration
- Cloud-based productivity strategies
- Small business solution
How Do Generative Engine Visibility Factors Differ from Traditional SEO Ranking Factors?
Generative engine visibility factors prioritize contextual relevance and semantic clarity over backlink authority and domain metrics that dominate traditional SEO.
Wellows research analyzing 21,767 domains reveals traditional authority scores (DA/DR) show near-zero correlation (r=0.00-0.21) with LLM citations, while content matching query intent achieves visibility independent of these metrics, fundamentally inverting the SEO hierarchy that governed search for two decades.
This conclusion is supported by SearchAtlas’s November 2025 study demonstrates that domains with lower authority often achieve equal or higher LLM visibility when content provides superior contextual alignment.
The Four Fundamental Differences
Difference #1: Authority Source Shift
Traditional SEO: Authority flows through backlinks. Sites with more high-quality backlinks rank higher, creating a “rich get richer” dynamic where established domains dominate.
Generative Engines: Authority flows through content quality and citations in context. A blog post from a low-DA site can outrank established publications if it provides better answers with verifiable data.
Wellows Analysis: SearchAtlas data shows Domain Rating (DR) correlates at r=0.00 (completely neutral) with ChatGPT citations and only r=0.14-0.17 with Perplexity and Gemini—far too weak to predict visibility.
Source: SearchAtlas Study, November 2025
Difference #2: Ranking Signal Hierarchy
| Traditional SEO Top Signals | Generative Engine Top Signals |
|---|---|
| 1️⃣ Backlink quantity/quality (DR/DA) | 1️⃣ Contextual relevance to query intent |
| 2️⃣ Domain authority & age | 2️⃣ Content comprehensiveness & data |
| 3️⃣ On-page keyword optimization | 3️⃣ Structured data (schema markup) |
| 4️⃣ Technical SEO (speed, mobile) | 4️⃣ E-E-A-T signals (author expertise) |
| 5️⃣ Content freshness | 5️⃣ Citation from trusted sources |
Key Insight: Notice that traditional SEO’s #1 signal (backlinks) doesn’t appear in the generative engine top 5. Meanwhile, schema markup, often optional in SEO, becomes essential for AI visibility.
Difference #3: Content Format Preferences
Wellows research, based on Writesonic’s analysis of 282,828,738 citations reveals LLMs show consistent content format preferences across all industries:
LLM Content Format Citation Rates (2025)
- Listicles & “Best of” articles: 20-30% of all citations (2.2-2.8x industry variation)
- Category hub pages: 9-11% of citations (2.4-3.7x variation)
- How-to documentation: 4-7% of citations (2.5-3.5x variation)
- Product pages: 4-6% of citations (4.7-5.8x variation)
- Case studies: 0.3-1.4% of citations (higher in Consumer Goods/ESG)
Source: Writesonic Industry Citation Analysis, November 2025
Traditional SEO favored long-form cornerstone content (2,000+ words) optimized around single keywords. Generative engines favor modular, structured content (comparison tables, bullet lists, FAQs) that LLMs can easily extract and recombine.
Difference #4: Freshness vs. Relevance Trade-off
“Content freshness gives significant ranking boosts in Perplexity, visibility may decline after 2-3 days without updates. But ChatGPT seems to favor comprehensive depth over recency, citing 2-3 year old articles if they provide better frameworks.”
- Perplexity AI: Heavy freshness bias (2-3 day window for peak visibility)
- ChatGPT: Moderate freshness bias (favors comprehensive depth even from older content)
- Gemini: Balanced approach (weighs both recency and comprehensiveness)
- Claude: Most variable—adapts freshness weighting based on query type
Source: Perplexity Ranking Factors Guide, Keyword.com, October 2025
What Still Matters from Traditional SEO?
Wellows research reveals these traditional SEO elements remain valuable for generative engine visibility:
- ✅ Technical performance: Page speed, mobile responsiveness, Core Web Vitals
- ✅ Content quality fundamentals: Accuracy, grammar, readability
- ✅ Topical authority: Comprehensive coverage of subject areas
- ✅ User engagement: Time on page, scroll depth (indirect signals)
- ✅ HTTPS & security: Trust indicators LLMs evaluate
❌ What matters less in 2025:
- Exact-match keyword density
- High DA/DR from backlink profiles alone
- Domain age without content quality
- Meta description optimization (LLMs read full content)
What are the Top Generative Engine Optimization tips for 2025?
At this point, you’ve probably realized visibility in generative engines isn’t about tricking a system—it’s about teaching the system to trust you.
For a step-by-step blueprint, see the Top GEO Tactics that marketing teams are using in 2025 to stay ahead.
If ChatGPT, Perplexity, or Gemini are going to pull you into a conversation about “the best productivity tools for 2025,” your content has to check a few key boxes—and not just the obvious ones.
Here’s a breakdown generative engine optimization tips for 2025 that you should follow:
Top Generative Engine Optimization Tips for 2025
Claim Your Spot with Bing Webmaster Tools
Before diving into content strategies, set up Bing Webmaster Tools. Most folks obsess over GSC data but forget Bing entirely. Yet, Bing powers ChatGPT’s web results — and showing up there can mean showing up in ChatGPT’s answers too.
Add Schema Markup for AI Search
Schema markup is the quiet MVP of LLM visibility. Add JSON-LD schema to your homepage and blog posts, especially Article, Organization, and Website schemas. This helps search engines and language models “understand” your content in context, improving your chances of being cited.
Write for Google, Bing, and LLMs at Once
Traditional SEO best practices still matter, a lot. Google rankings often translate into LLM citations. If you’re already writing content that ranks well, keep it up, just level up with LLM-specific nuances.
Use Autocomplete to Discover NLP-Friendly Queries
LLMs love structured questions and clean answers. That means your H2s should reflect real queries, and your paragraphs should answer them directly in a style that reads like ChatGPT wrote it.
Keep Content Fresh with Updated Publish Dates
ChatGPT often favors newer content when citing sources. So revisit and update your existing blog posts every 3–6 months. Add new insights, remove outdated info, and most importantly, update the publish date (and make sure your schema reflects that).
Avoid Publishing Raw AI-Generated Content
Yes, this sounds ironic, but don’t let AI write your articles for you. LLMs don’t like echo chambers. When you publish something that was created by a model, you’re feeding models their own output, and that dilutes originality.
Get Mentioned on Other Sites
Citations matter, but backlinks aren’t the only way in. LLMs scan for mentions, not just hyperlinks. Even without a clickable link, your brand name in plain text helps models associate you with authority. It’s PR for the AI age, and digital PR strategies are now essential to model visibility.
Grow Your Branded Search Volume
Build brand demand. If more people search for “[Your Brand] productivity platform” or “[Your Brand] AI tools”, you send a signal to both search engines and LLMs that you’re trusted and in demand.
Add Multimedia: Not Just for Looks, But for Context
LLMs can’t watch videos, but they do learn from transcripts, image captions, and metadata. Want to explain the difference between traditional SEO and GEO? Create a simple infographic. Add alt text. Or embed a 2-minute video walking through an example.
Build Authoritative, Quote-Worthy Content
This one’s simple but powerful: Use stats from credible studies. Link to trusted sources. Include expert quotes (even if it’s you explaining something with authority).
Still, brands face common challenges in achieving generative engine visibility—such as model bias, rapid updates, and the dominance of a few authority domains. Keeping up with the latest trends in generative engine visibility and monitoring different perspectives on generative engine visibility helps identify gaps and opportunities, which can be tracked effectively through GEO performance KPIs.
Comparing Top Generative Engine Optimization Platforms for AI Visibility
Generative Engine Optimization (GEO) platforms are becoming indispensable for brands aiming to secure visibility within AI-powered search results. Below is a comparison of some of the top GEO platforms shaping 2025:
Geneo.app
Among the pioneers of GEO, Geneo provides real-time monitoring across leading AI engines such as ChatGPT and Google AI Overview. Its strengths include advanced optimization workflows, competitor benchmarking, and detailed performance histories.
AthenaHQ
Designed for holistic AI visibility, AthenaHQ delivers a full-spectrum dashboard covering Share of Voice, sentiment analysis, prompt performance, and multi-language tracking—making it particularly useful for global brands.
BrightEdge
Traditionally known for enterprise SEO, BrightEdge has expanded into GEO with AI citation monitoring, competitor intelligence, and early detection of algorithmic changes—bridging classic SEO and AI search optimization.
Semrush AI Toolkit
Built into the familiar Semrush ecosystem, this toolkit identifies AI-triggered queries, tracks AI Overview appearances, and analyzes prompt rewrites—bringing GEO directly into mainstream SEO workflows.
Rankscale AI
Focused on precision, Rankscale AI provides an AI Search Readiness Score, citation analysis, granular term tracking, and benchmarking against competitors—ideal for brands seeking deep, performance-driven insights.
These platforms vary in scope—from enterprise-grade monitoring (BrightEdge, Semrush) to specialized GEO-first solutions (Geneo, Rankscale, AthenaHQ)—giving marketers the flexibility to choose based on brand scale, goals, and resources.
Read More Articles
- Client Onboarding Checklist for AI Visibility Platforms
- AI Algorithm Updates: SEO Impact & Recovery Tips
- Boost AI Search Visibility with Knowledge Graphs
- AI Search Marketing: ChatGPT vs Traditional Search
- How Will Google’s AI Mode Transform Traditional SEO Practices?
- How to Become a Trusted Source in AI Search
- How to Design Content Briefs for GEO?
- Top 10 Visibilty Tips for Gemini AI
- Top 10 Visibilty Tips for ChatGPT
- Top 10 Visibilty Tips for Perplexity
- Top 10 Visibilty Tips for Claude
- What Roles Does Structured Data Play in LLM Visibility?
- How AI Search Marketing Strategies Target Semantic Search Intent (2026)
FAQs
The fastest win is adding a concise “Key Takeaways” box at the top that directly answers user queries, combined with question-style subheadings and JSON-LD FAQ markup. Verifying and submitting your pages in Bing Webmaster Tools often yields an immediate lift in AI-driven results.
Aim to update evergreen articles every quarter—refresh statistics, examples, and the “Last Updated” date—while performing brief monthly checks on rapidly evolving topics and triggering immediate audits after major AI model releases or industry reports.
Absolutely—you should maintain core SEO fundamentals like site speed, mobile responsiveness, and keyword targeting while layering in GEO elements such as conversational-query headings, structured data markup, and FAQ sections to capture both blue-link traffic and AI-powered citations.
How Wellows Helps You Master Generative Engine Visibility
Understanding generative engine visibility factors is one challenge; tracking, optimizing, and improving your AI visibility at scale is another. This is where Wellows transforms strategy into measurable results.
The Generative Engine Visibility Challenge
In 2025, brands face a fundamental problem: AI search engines cite sources differently than Google ranks pages, and traditional SEO tools can’t track LLM citations across ChatGPT, Gemini, Perplexity, and Claude simultaneously.
You’ve learned throughout this guide that:
- Domain Authority shows near-zero correlation (r=0.00-0.21) with LLM visibility
- Content format matters—listicles get 20-30% citation share
- Structured data increases citations by 28-40%
- Contextual relevance outweighs backlink authority
But how do you actually measure your visibility across AI engines? How do you know if your content optimization efforts are working? Where are competitors getting cited that you’re not?
Introducing Wellows: The Autonomous Marketing Platform for AI Visibility
Wellows is the AI visibility platform that helps brands:
- ✅ Track your Citation Score across ChatGPT, Claude, Perplexity, and Gemini in one unified metric
- ✅ Discover missed citations where competitors appear in AI responses and you don’t
- ✅ Monitor AI visibility trends with daily tracking and alerting
- ✅ Uncover strategic insights about which queries drive citations and where to focus content efforts
- ✅ Measure ROI of GEO investments with quantifiable visibility metrics
Core Wellows Features That Solve Visibility Challenges
1. Citation Score: Your AI Visibility KPI
What it is: Citation Score aggregates your brand mentions across ChatGPT, Claude, Perplexity, and Gemini into a single metric you can measure, report on, and improve—finally giving you a KPI that reflects where buying decisions actually happen.
Why it matters: Traditional metrics (DA, DR, organic traffic) don’t predict AI citations. Citation Score is the first metric specifically designed for the generative engine era.
How Wellows helps:
- Track Citation Score changes week-over-week
- Compare your score to competitors
- Identify which LLMs cite you most frequently
- Set improvement targets and measure progress
2. Implicit Citations: Discover Missed Opportunities
What it is: Implicit citations surface the domains and publishers that mention your competitors but ignore you, then hand you verified contact details to close the gap.
Why it matters: As we documented in this guide, LLMs cite sources based on off-site mentions and trust signals. Implicit citations show exactly where those gaps exist.
How Wellows helps:
- Identify publications citing competitors 5-10x more than you
- Get verified contact information for outreach
- Prioritize high-impact opportunities by citation frequency
- Turn visibility blind spots into actionable outreach campaigns
3. Explicit Citations: Understand Query-Level Visibility
What it is: Explicit citations reveal the exact queries where rival brands appear in AI responses and provide the keyword insights your team needs to create content that competes.
Why it matters: LLMs generate diverse queries from single keywords (as we showed with “productivity tools” generating 12+ distinct queries). You need to know which specific prompts drive citations.
How Wellows helps:
- See which queries trigger competitor citations
- Analyze content formats that win for specific queries
- Identify gaps where no brand dominates (opportunity zones)
- Map query variations LLMs associate with your keywords
4. Competitive Insights: Strategic Benchmarking
What it is: Wellows competitive insights compare your citation performance to that of rivals across topics, providing managers with a strategic view and teams with a clear sense of where to focus next.
Why it matters: You can’t improve what you can’t measure relative to competition. Traditional rank tracking doesn’t work for AI citations.
How Wellows helps:
- Benchmark Citation Score against 3-10 competitors
- Identify topics where you lag behind rivals
- Discover topics where you lead (double down opportunities)
- Track competitive movements week-over-week
5. Topics & Queries: Precision Management
What it is: Topics & Queries organize the prompts and question patterns your audience uses, track how often your brand appears in responses, and let you adjust your query universe as your strategy shifts.
Why it matters: As documented in this guide, a single keyword spawns dozens of LLM-generated queries. You need to track visibility across all variations.
How Wellows helps:
- Create custom topic clusters for tracking
- Add/remove queries as priorities shift
- Monitor citation frequency per query
- Identify high-volume, low-citation opportunities
6. Monitoring: Real-Time Visibility Tracking
What it is: Monitoring tracks how your Citation Score moves week to week, flags sudden drops or surges, and keeps you informed on competitor activity, with zero manual effort.
Why it matters: As we documented with Reddit’s citation drop from 29% to 5% in September 2025, AI visibility can shift rapidly. You need real-time awareness.
How Wellows helps:
- Automated weekly Citation Score tracking
- Alerts for significant visibility changes (+/- 15%)
- Competitor movement notifications
- Historical trend analysis (6-12 month views)
- Platform-specific insights (which LLM is driving changes)
How Wellows Transforms the Insights from This Guide into Action
Throughout this guide, you’ve learned that:
| Key Finding from This Guide | How Wellows Helps You Act On It |
|---|---|
| Traditional authority metrics (DA/DR) show r=0.00-0.21 correlation with LLM visibility | Wellows tracks Citation Score (actual LLM mentions) instead of backlink-based metrics, giving you the right KPI |
| Listicles get 20-30% of citations, category hubs get 9-11% | Wellows shows which content formats competitors use for high-citation queries, guide your content strategy |
| Contextual relevance is the strongest predictor of visibility | Wellows reveals exact queries where competitors get cited, optimize for precise intent matching |
| Reddit citations, review platforms, and community discussions influence LLM trust | Wellows Implicit Citations identify publishers mentioning competitors, target for PR outreach |
| ChatGPT prefers comprehensive depth, Perplexity prioritizes freshness (2-3 day boost) | Wellows tracks platform-specific citation patterns, tailor content updates by LLM preference |
| Schema markup increases citations by 28-40% | Wellows monitoring detects visibility changes after schema implementation—measure actual impact |
Who Benefits from Wellows?
For Marketing Teams & Directors
- 📊 Unified visibility dashboard: Track AI citations across all platforms in one place
- 🎯 Clear ROI measurement: Quantify GEO investment impact with Citation Score trends
- 🚀 Competitive intelligence: Know where competitors win and you don’t
- ⚡ Strategic prioritization: Focus content efforts on the highest-impact opportunities
For Agencies Serving Clients
- 📈 Client reporting simplified: Citation Score provides a clear, client-friendly metric
- 🔍 Opportunity identification: Show clients exactly where they’re missing citations
- 💼 Service differentiation: Offer GEO alongside traditional SEO
- 📱 Multi-client dashboard: Manage AI visibility for entire client portfolio
Learn more: AI Search Visibility Platform for Agencies
For Freelancers & Solopreneurs
- 🎨 Personal brand tracking: Monitor how LLMs cite your expertise
- 📝 Content strategy guidance: Discover which topics/formats drive citations
- 🔧 Lightweight implementation: No enterprise complexity, just actionable insights
- 💡 Competitive edge: Understand AI visibility dynamics that larger competitors miss
Learn more: AI Search Visibility Platform for Freelancers
The Wellows Difference: Autonomous Marketing Platform
Unlike traditional SEO tools that simply report data, Wellows is an autonomous marketing platform that:
- ✅ Automatically discovers new citation opportunities
- ✅ Continuously monitors AI visibility changes across platforms
- ✅ Proactively alerts you to competitive movements
- ✅ Streamlines complex tasks into simple dashboards
- ✅ Eliminates inefficiencies of manual LLM testing
From Research to Results: The Wellows Research Foundation
The insights in this guide are powered by Wellows’ proprietary research:
Wellows Insights: What 7,000+ ChatGPT Queries Reveal About Brand Visibility in AI Search
From 485,000 citations across 38,000 domains, we uncovered why LLMs trust some sources over others, reshaping how brands gain visibility in AI-driven search.
This research foundation, combined with daily tracking across ChatGPT, Gemini, Perplexity, AI Overviews, and AI Mode, gives Wellows users an unfair advantage in the generative engine era.
Ready to Master Generative Engine Visibility?
The shift from traditional search to AI-powered discovery is happening now. Brands that track and optimize for LLM citations today will dominate AI-driven buyer journeys tomorrow.
🚀 See How Your Brand Performs in AI Search
Get a personalized analysis of your Citation Score across ChatGPT, Gemini, Perplexity, AI Overviews, and AI Mode and discover where competitors are getting cited that you’re not.
Join forward-thinking marketers building authority across both Google search and AI-powered answers.
